c语言基础知识
用于记录 c 语言基础知识,如果没有特别说明本文的所有代码编译环境为 gcc 编译器编译,学习资料来自狄泰软件学院可在淘宝购买学习
一、基本数据类型
¶1、数据类型
- 含义
固定内存大小的别名
- 作用
创建变量
c语言数据类型表
Type
Storage size
Value range Precision
char
1 byte
-128 to 127 or 0 to 255
unsigned char
1 byte
0 to 255
signed char
1 byte
-128 to 127
int
2 or 4 bytes
-32,768to32,767 or -2,147,483,648 to 2,147,483,647
unsigned int
2 or 4 bytes
0 to 65,535 or 0 to 4,294,967,295
short
2 bytes
-32,768 to 32,767
unsigned short
2 bytes
0 to 65,535
long
4 bytes
-2,147,483,648 to 2,147,483,647
unsigned long
4 bytes
0 to 4,294,967,295
float
4 byte
1.2E-38 to 3.4E+38 6 decimal places
double
8 byte
2.3E-308 to 1.7E+308 15 decimal places
long double
10 byte
3.4E-4932 to 1.1E+4932 19 decimal places
¶2、变量
-
本质
一段连续存储空间的别名,大小由创建的数据类型定
-
作用
程序通过变量申请储存空间
通过变量名使用储存空间
通过变量名区分相同大小相同类型的内存空间
-
补充
sizeof关键字用来计算变量,类型,字符串,数组,或结构体等所占内存空间大小
-
重新命名一个数据类型
通过 typedef 关键字重新命名一个数据类型
¶3、编程实验
¶编程实验1:数据类型与变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
int main(int argv, char* argc[])
{
char a = 0;
short b = 0;
int c = 0;
printf("sizeof(char) = %d\n", (int)sizeof(char));
printf("sizeof(a) = %d\n\n", (int)sizeof(a));
printf("sizeof(short) = %d\n", (int)sizeof(short));
printf("sizeof(b) = %d\n\n", (int)sizeof(b));
printf("sizeof(int) = %d\n", (int)sizeof(int));
printf("sizeof(c) = %d\n\n", (int)sizeof(c));
return 0;
}
运行结果:
sizeof(char) = 1
sizeof(a) = 1
sizeof(short) = 2
sizeof(b) = 2
sizeof(int) = 4
sizeof(c) = 4
¶编程实验2:typedef自定义数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
typedef int INT32;
typedef unsigned char BYTE;
typedef struct _tags_ts
{
BYTE b1;
BYTE b2;
short s;
INT32 i;
}TS;
int main(int argv, char* argc[])
{
INT32 i32;
BYTE b;
TS ts;
printf("%d, %d\n", (int)sizeof(INT32), (int)sizeof(i32));
printf("%d, %d\n", (int)sizeof(BYTE), (int)sizeof(b));
printf("%d, %d\n", (int)sizeof(TS), (int)sizeof(ts));
return 0;
}
运行结果:
4, 4
1, 1
8, 8
二、有符号数与无符号数
¶1、有符号数
- 声明
默认为有符号数,用 signed 关键字声明
- 数据类型的最高位用来标识数据的符号
最高位为1表示这个数为负数
最高位为0表示这个数为正数
- 有符号数的表示方法:在计算机内部用补码表示有符号数
正数的补码为正数本身
负数的补码为对应的正数的反码加1
¶2、无符号数
- 声明
用 unsigned 关键字声明,不能声明浮点型 float double
- 特点
默认为正数
没有符号位
最大值 + 1 = 最小值
最小值 - 1 = 最大值
有符号数与无符号整形数(unsigned int)混合运算,有符号会被转换为无符号数,结果为无符号数
¶3、编程实验
¶编程实验1:证明有符号数的表示方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(int argv, char* argc[])
{
char c = -5;
short s = 6;
int i = -7;
printf("%d\n", (int)( (c&0x80) !=0 ));
printf("%d\n", (int)( (s&0x8000) !=0 ));
printf("%d\n", (int)( (i&0x80000000) !=0 ));
return 0;
}
运行结果:
1
0
1
¶编程实验2:有符号数与无符号数的混合运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(int argv, char* argc[])
{
unsigned int i = 5;
int j = -10;
if((i+j) < 0)
{
printf("i+j < 0\n");
}else{
printf("i+j > 0\n");
}
return 0;
}
运行结果:
i+j > 0
¶编程实验3:无符号数(最小值 - 1 = 最大值)
1
2
3
4
5
6
7
8
9
10
11
12
13
int main(int argv, char* argc[])
{
unsigned int i = 0;
for(i = 9; i>=0; i--)
printf("i =%d\n",i);
return 0;
}
运行结果: 程序死循环打印
三、内存中的浮点数(float double)
¶1、存储方式
符号位,指数,尾数
存储表
类型
符号
指数
尾数
float
1位(第31位)
8位(第23-30位)
23位(第0-22位)
double
1位(第63位)
11位(第52-62位)
52位(第0-51位)
¶2、浮点数转换(十进制)
1)将浮点数转换为二进制
2)用科学计数法表示二进制浮点数
3)计算指数偏移后的值 (指数+偏移量)
4)偏移量: float 127
double 1023
¶3、8.25的float的表示
- 转换为二进制数
8.25 ==> 1000.01
- 用科学计数法表示二进制浮点数
100.01 ==> 1.00001 *2^3
- 计算指数偏移后的值
3 + 127 = 130 ==> 1000 0010
- 小数部分
00001
- 内存中的表示
0x41040000
0(符号) 1000 0010(指数) 00001 0000000000000000(小数)
- 补充知识点:
十进制小数转为二进制小数(乘2取整)
例子:0.25
0.25 x 2 = 0.5 取整是0
0.5 x 2 = 1.0 取整是1
即 0.25 的二进制表示方法为 0.01
¶4、浮点型的秘密(重点)
-
float可以表示的具体数值个数与int类型相同
-
flaot可表示的数字之间是不连续的,存在间隙
-
float只是一种近似的表示法,不能作为精确数使用
-
float的运算速度比int慢的多
¶5、编程实验
¶编程实验1:8.25 float的表示
1
2
3
4
5
6
7
8
9
10
11
12
13
int main(int argv, char* argc[])
{
float f = 8.25;
unsigned int* p = (unsigned int*)&f;
printf("0x%x\n", *p);
return 0;
}
运行结果:0x41040000
¶编程实验2:float 类型的不精确性,与不连续性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main(int argv, char* argc[])
{
float f = 3.14;
float f1 = 123456789;
printf("f = %0.10f\n", f);
printf("f1 = %0.10f\n", f1);
return 0;
}
运行结果:
f = 3.1400001049
f1 = 123456792.0000000000
四、数据类型之间的转换
¶1、强制类型转换
(type)var_name
(type)vale
转换结果:
1)目标类型能够容纳目标值:结果不变
2)目标类型不能容纳目标值:结果将产生截断保留低位丢掉高位
例:float转换为 int ,直接丢掉小数部分
3)不是所有的强制类型转换都能成功,不能转换编译器报错
例:结构体转换为 int 类型
¶2、隐式类型转换
编译器主动进行的转换
低类型:占用字节数相对较小的变量
高类型:占用字节数相对较高的变量
1)转换的安全性
a)低类型到高类型的转换时是安全的,不会产生截断
b)高类型到低类型的转换时是不安全的,会产生截断,产生不正确的结果
2)转换发生点:
a)算数运算,低类型转换为高类型
b)赋值表达式中,表达式中的右值类型转换为左值的类型
c)函数调用时,形参转换为实参的类型
d)函数返回值,return表达式后面的返回值转换为返回值类型

¶3、编程实验
¶编程实验1:强制类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
typedef struct tag_ts
{
int i;
int j;
}TS;
TS ts;
int main(int argv, char* argc[])
{
short s = 0x1122;
char c = (char)s; // 0x22
int i = (int)s; // 0x1122
int j = (int)3.123; // 3
unsigned int p = (unsigned int)&ts; // 64位机器产生截断,32位机器正常转换
// long l = (long)ts; // 转换失败编译报错
// ts = (TS)s; // 转换失败编译报错
printf("c = 0x%x\n", c);
printf("i = 0x%x\n", i);
printf("j = 0x%x\n", j);
printf("p = 0x%x\n", p);
return 0;
}
运行结果:
c = 0x22
i = 0x1122
j = 0x3
p = 0x3558018
¶编程实验2:隐式类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int main(int argv, char* argc[])
{
char c = 'a';
int i = c;
unsigned int j = 0x11223344;
short s = j;
printf("c = %c\n", c); // a
printf("i = %d\n", i); // 97
printf("j = 0x%x\n", j); // 0x11223344
printf("s = 0x%x\n", s); // 0x3344
printf("sizeof(c+s):%ld\n", sizeof(c+s)); // 4
return 0;
}
运行结果
c = a
i = 97
j = 0x11223344
s = 0x3344
sizeof(c+s):4
五、分支语句
¶1、if 语句分析
- 多用于复杂逻辑进行判断
- 与零值比较注意点
1)bool 型变量应该直接出现在条件中,不要进行比较
2)变量和 0 字面常量比较,0 字面常量应该出现在比较符的左边
3)float 不能直接和 0 进行比较,需要定义精度
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void f1(int i)
{
if( i < 6 )
{
printf("Failed!\n");
}
else if( (6 <= i) && (i <= 8) )
{
printf("Good!\n");
}
else
{
printf("Perfect!\n");
}
}
int main()
{
f1(5); // Failed!
f1(9); // Perfect!
f1(7); // Good!
return 0;
}
输出结果:
Failed!
Perfect!
Good!
¶2、switch 语句分析
- 多用于多分支判断
1)必须要有 break ,否则会导致分支重叠
2)case 语句中的值只能是整形或者字符型
3)按字母或者数字顺序排列各条语句
4)正常的放在前面,异常的放在后面
5)default 必须加上,只用于处理正真异常的情况
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
void f2(char i)
{
switch(i)
{
case 'c':
printf("Compile\n");
break;
case 'd':
printf("Debug\n");
break;
case 'o':
printf("Object\n");
break;
case 'r':
printf("Run\n");
break;
default:
printf("Unknown\n");
break;
}
}
int main()
{
f2('o'); // Object
f2('d'); // Debug
f2('e'); // Unknown
return 0;
}
运行结果:
Object
Debug
Unknown
¶3、循环语句
-
for 先判断,适用于循环次数固定的循环
-
while 先判断,适用于循环次数不固定的场合
-
do while 循环至少执行一次循环体
-
break 和 continue 的区别
break 表示终止循环
continue 表示终止本次循环,进入下次循环
-
do while(0) 巧妙使用,释放内存空间,避开内存泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int test()
{
int *ptr = malloc(...);
do
{
dosomething...;
if(error)
break;
dosomething...;
if(error)
break;
dosomething...;
}
while(0);
free(ptr);
return 0;
}
六、c语言变量属性
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用
- 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
register int j = 0; // 向编译器申请将 j 存储于寄存器中
printf("%p\n", &j); // error
return 0;
}
运行结果:
a.c:7: error: address of register variable ‘j’ requested
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区
- 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int f1()
{
int r = 0;
r++;
return r;
}
int f2()
{
static int r = 0;
r++;
return r;
}
int main()
{
auto int i = 0; // 显示声明 auto 属性,i 为栈变量
static int k = 0; // 局部变量 k 的存储区位于静态区,作用域位于 main 中
printf("&i = %p\n", &i);
printf("&j = %p\n", &k);
for(i=0; i<5; i++)
{
printf("%d\n", f1()); // 1,1,1,1,1
}
printf("\n");
for(i=0; i<5; i++)
{
printf("%d\n", f2()); // 1,2,3,4,5
}
return 0;
}
运行结果:
&i = 0xbfa141cc
&k = 0x804a020
1
1
1
1
1
1
2
3
4
5
编程实验2,修饰全局变量
1
2
3
4
5
6
7
8
9
//头文件 a.h
static int g_i;
static int g_j;
int getI() //使用是这个方式获得static声明的全局变量
{
return g_i;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//c文件
extern int getI();
extern int g_j;
int main()
{
printf("%d\n", g_j); // ERROR
printf("%d\n", getI()); // 0
return 0;
}
运行结果:
5-2.c:(.text+0xb): undefined reference to `g_j'
说明:
注释掉 printf("%d\n", g_j);正常运行输出 0
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
extern int i;
printf("i = %d\n",i);
return 0;
}
int i = 1;
运行结果:
i = 1
- “告诉”c++编译器用c方式编译
1
2
3
4
5
6
7
8
extern "C"
{
/*...*/
}
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void func(int n)
{
int* p = NULL;
if(n < 0)
{
goto STATUS;
}
p = (int*)malloc(sizeof(int)*n);
STATUS:
p[0] = n;
free(p);
}
int main(int argv, char* argc[])
{
printf("begin ...\n");
printf("func(1)\n");
func(1); // 正常运行
printf("func(-1)\n");
func(-1); // 内核崩溃
printf("end\n");
return 0;
}
运行结果:
begin ...
func(1)
func(-1)
Segmentation fault (core dumped)
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
const int g_cc = 2;
int main()
{
const int cc = 1;
int* p = (int*)&cc;
printf("cc = %d\n", cc); // cc = 1
*p = 3;
printf("cc = %d\n", cc); // cc = 3
p = (int*)&g_cc;
printf("g_cc = %d\n", g_cc); // g_cc = 2
*p = 4; // error
printf("g_cc = %d\n", g_cc);
return 0;
}
运行结果:
cc = 1
cc = 3
g_cc = 2
段错误
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1
const char* s = ”hello word”; //字符串字面量

¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用

编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0

¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
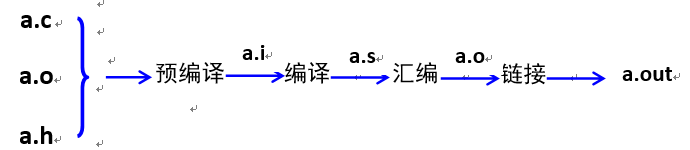
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
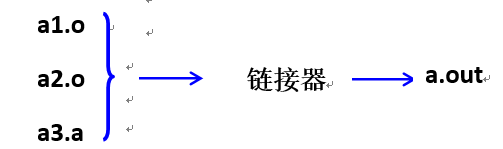
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out

知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件

程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
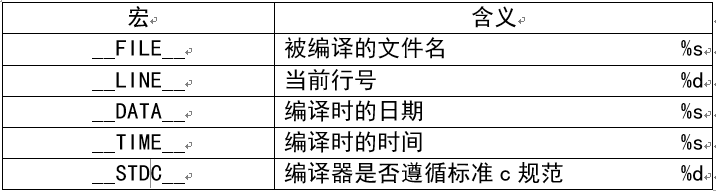
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])

¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
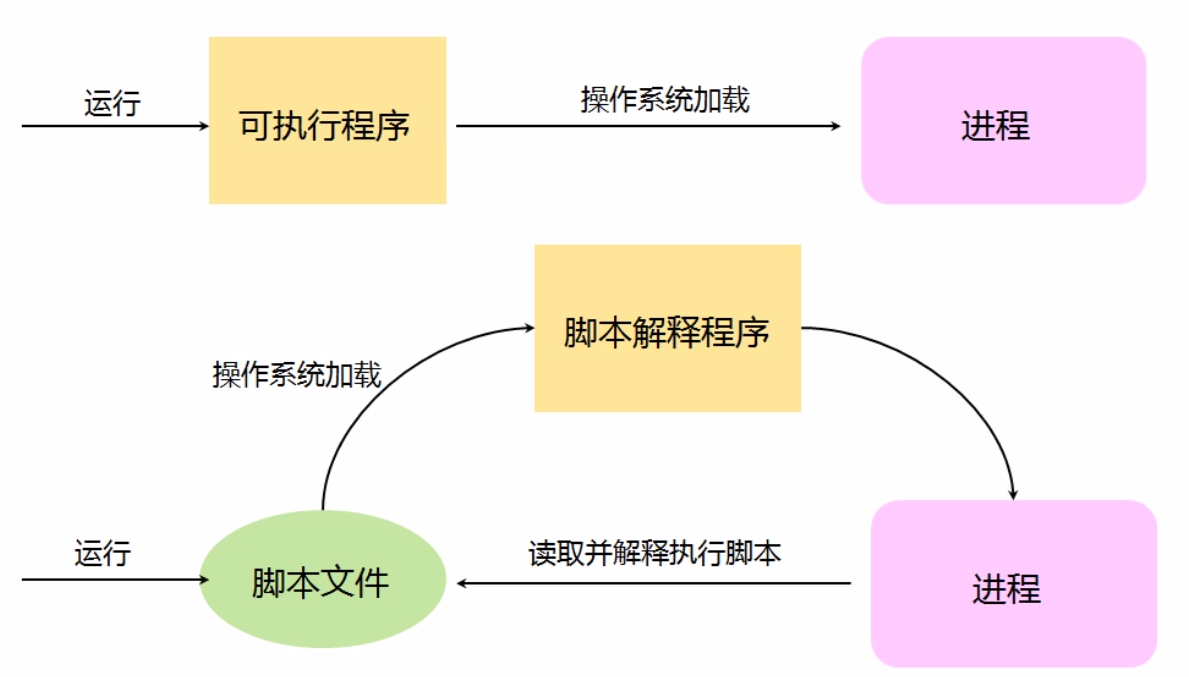
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
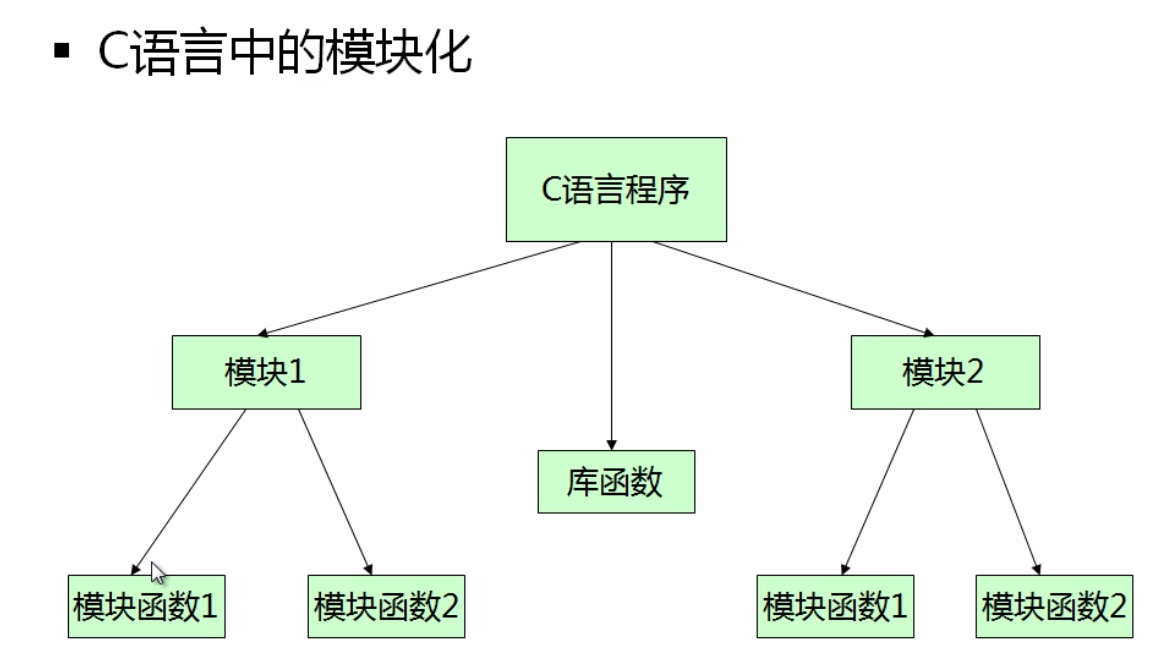
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
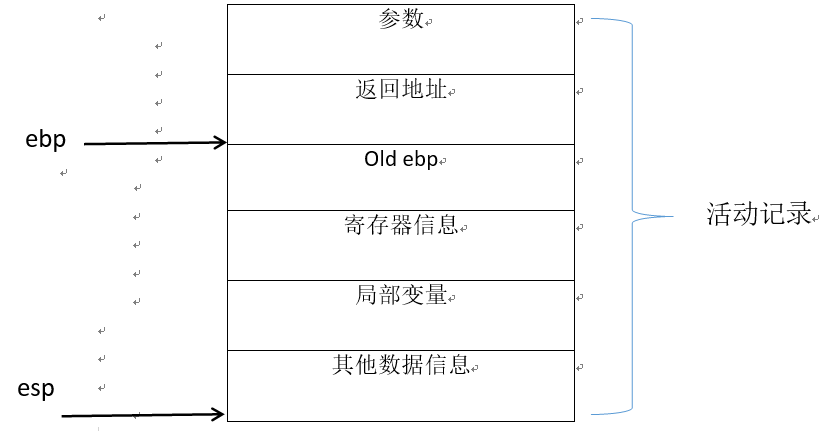
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
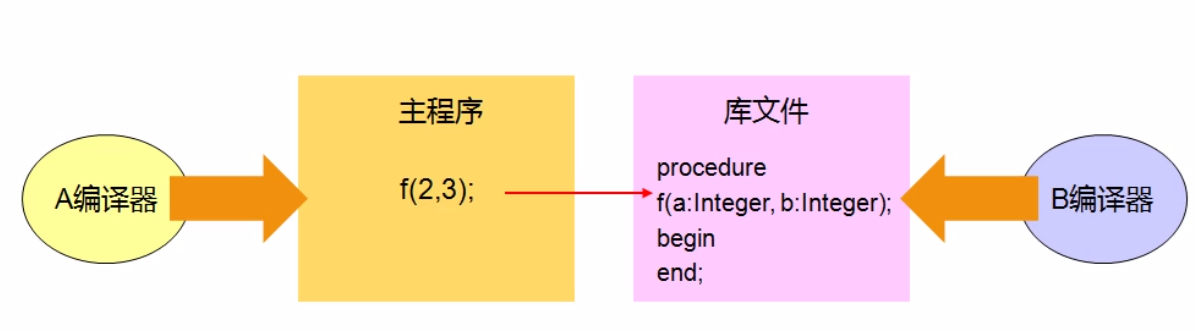
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束

¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
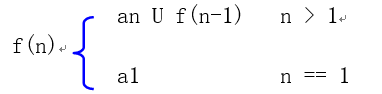
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
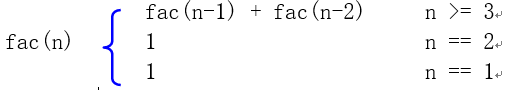
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
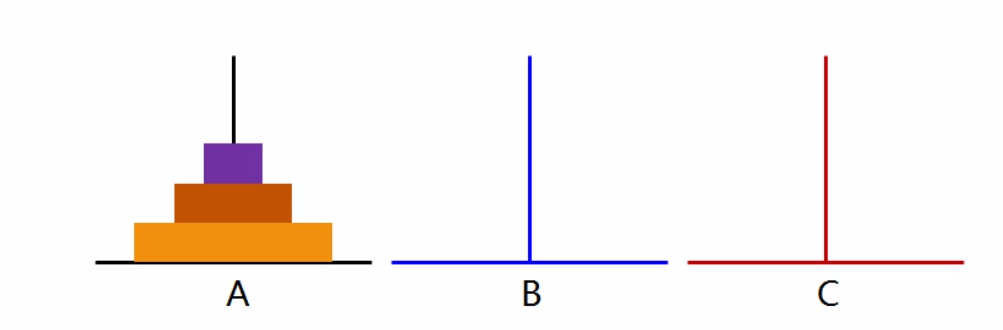
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱

1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、数据类型
- 含义
固定内存大小的别名
- 作用
创建变量
| c语言数据类型表 | ||
|---|---|---|
| Type | Storage size | Value range Precision |
| char | 1 byte | -128 to 127 or 0 to 255 |
| unsigned char | 1 byte | 0 to 255 |
| signed char | 1 byte | -128 to 127 |
| int | 2 or 4 bytes | -32,768to32,767 or -2,147,483,648 to 2,147,483,647 |
| unsigned int | 2 or 4 bytes | 0 to 65,535 or 0 to 4,294,967,295 |
| short | 2 bytes | -32,768 to 32,767 |
| unsigned short | 2 bytes | 0 to 65,535 |
| long | 4 bytes | -2,147,483,648 to 2,147,483,647 |
| unsigned long | 4 bytes | 0 to 4,294,967,295 |
| float | 4 byte | 1.2E-38 to 3.4E+38 6 decimal places |
| double | 8 byte | 2.3E-308 to 1.7E+308 15 decimal places |
| long double | 10 byte | 3.4E-4932 to 1.1E+4932 19 decimal places |
¶2、变量
-
本质
一段连续存储空间的别名,大小由创建的数据类型定 -
作用
程序通过变量申请储存空间
通过变量名使用储存空间
通过变量名区分相同大小相同类型的内存空间 -
补充
sizeof关键字用来计算变量,类型,字符串,数组,或结构体等所占内存空间大小 -
重新命名一个数据类型
通过 typedef 关键字重新命名一个数据类型
¶3、编程实验
¶编程实验1:数据类型与变量
1 |
|
¶编程实验2:typedef自定义数据类型
1 |
|
二、有符号数与无符号数
¶1、有符号数
- 声明
默认为有符号数,用 signed 关键字声明
- 数据类型的最高位用来标识数据的符号
最高位为1表示这个数为负数
最高位为0表示这个数为正数
- 有符号数的表示方法:在计算机内部用补码表示有符号数
正数的补码为正数本身
负数的补码为对应的正数的反码加1
¶2、无符号数
- 声明
用 unsigned 关键字声明,不能声明浮点型 float double
- 特点
默认为正数
没有符号位
最大值 + 1 = 最小值
最小值 - 1 = 最大值
有符号数与无符号整形数(unsigned int)混合运算,有符号会被转换为无符号数,结果为无符号数
¶3、编程实验
¶编程实验1:证明有符号数的表示方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(int argv, char* argc[])
{
char c = -5;
short s = 6;
int i = -7;
printf("%d\n", (int)( (c&0x80) !=0 ));
printf("%d\n", (int)( (s&0x8000) !=0 ));
printf("%d\n", (int)( (i&0x80000000) !=0 ));
return 0;
}
运行结果:
1
0
1
¶编程实验2:有符号数与无符号数的混合运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(int argv, char* argc[])
{
unsigned int i = 5;
int j = -10;
if((i+j) < 0)
{
printf("i+j < 0\n");
}else{
printf("i+j > 0\n");
}
return 0;
}
运行结果:
i+j > 0
¶编程实验3:无符号数(最小值 - 1 = 最大值)
1
2
3
4
5
6
7
8
9
10
11
12
13
int main(int argv, char* argc[])
{
unsigned int i = 0;
for(i = 9; i>=0; i--)
printf("i =%d\n",i);
return 0;
}
运行结果: 程序死循环打印
三、内存中的浮点数(float double)
¶1、存储方式
符号位,指数,尾数
存储表
类型
符号
指数
尾数
float
1位(第31位)
8位(第23-30位)
23位(第0-22位)
double
1位(第63位)
11位(第52-62位)
52位(第0-51位)
¶2、浮点数转换(十进制)
1)将浮点数转换为二进制
2)用科学计数法表示二进制浮点数
3)计算指数偏移后的值 (指数+偏移量)
4)偏移量: float 127
double 1023
¶3、8.25的float的表示
- 转换为二进制数
8.25 ==> 1000.01
- 用科学计数法表示二进制浮点数
100.01 ==> 1.00001 *2^3
- 计算指数偏移后的值
3 + 127 = 130 ==> 1000 0010
- 小数部分
00001
- 内存中的表示
0x41040000
0(符号) 1000 0010(指数) 00001 0000000000000000(小数)
- 补充知识点:
十进制小数转为二进制小数(乘2取整)
例子:0.25
0.25 x 2 = 0.5 取整是0
0.5 x 2 = 1.0 取整是1
即 0.25 的二进制表示方法为 0.01
¶4、浮点型的秘密(重点)
-
float可以表示的具体数值个数与int类型相同
-
flaot可表示的数字之间是不连续的,存在间隙
-
float只是一种近似的表示法,不能作为精确数使用
-
float的运算速度比int慢的多
¶5、编程实验
¶编程实验1:8.25 float的表示
1
2
3
4
5
6
7
8
9
10
11
12
13
int main(int argv, char* argc[])
{
float f = 8.25;
unsigned int* p = (unsigned int*)&f;
printf("0x%x\n", *p);
return 0;
}
运行结果:0x41040000
¶编程实验2:float 类型的不精确性,与不连续性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main(int argv, char* argc[])
{
float f = 3.14;
float f1 = 123456789;
printf("f = %0.10f\n", f);
printf("f1 = %0.10f\n", f1);
return 0;
}
运行结果:
f = 3.1400001049
f1 = 123456792.0000000000
四、数据类型之间的转换
¶1、强制类型转换
(type)var_name
(type)vale
转换结果:
1)目标类型能够容纳目标值:结果不变
2)目标类型不能容纳目标值:结果将产生截断保留低位丢掉高位
例:float转换为 int ,直接丢掉小数部分
3)不是所有的强制类型转换都能成功,不能转换编译器报错
例:结构体转换为 int 类型
¶2、隐式类型转换
编译器主动进行的转换
低类型:占用字节数相对较小的变量
高类型:占用字节数相对较高的变量
1)转换的安全性
a)低类型到高类型的转换时是安全的,不会产生截断
b)高类型到低类型的转换时是不安全的,会产生截断,产生不正确的结果
2)转换发生点:
a)算数运算,低类型转换为高类型
b)赋值表达式中,表达式中的右值类型转换为左值的类型
c)函数调用时,形参转换为实参的类型
d)函数返回值,return表达式后面的返回值转换为返回值类型
¶3、编程实验
¶编程实验1:强制类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
typedef struct tag_ts
{
int i;
int j;
}TS;
TS ts;
int main(int argv, char* argc[])
{
short s = 0x1122;
char c = (char)s; // 0x22
int i = (int)s; // 0x1122
int j = (int)3.123; // 3
unsigned int p = (unsigned int)&ts; // 64位机器产生截断,32位机器正常转换
// long l = (long)ts; // 转换失败编译报错
// ts = (TS)s; // 转换失败编译报错
printf("c = 0x%x\n", c);
printf("i = 0x%x\n", i);
printf("j = 0x%x\n", j);
printf("p = 0x%x\n", p);
return 0;
}
运行结果:
c = 0x22
i = 0x1122
j = 0x3
p = 0x3558018
¶编程实验2:隐式类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int main(int argv, char* argc[])
{
char c = 'a';
int i = c;
unsigned int j = 0x11223344;
short s = j;
printf("c = %c\n", c); // a
printf("i = %d\n", i); // 97
printf("j = 0x%x\n", j); // 0x11223344
printf("s = 0x%x\n", s); // 0x3344
printf("sizeof(c+s):%ld\n", sizeof(c+s)); // 4
return 0;
}
运行结果
c = a
i = 97
j = 0x11223344
s = 0x3344
sizeof(c+s):4
五、分支语句
¶1、if 语句分析
- 多用于复杂逻辑进行判断
- 与零值比较注意点
1)bool 型变量应该直接出现在条件中,不要进行比较
2)变量和 0 字面常量比较,0 字面常量应该出现在比较符的左边
3)float 不能直接和 0 进行比较,需要定义精度
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void f1(int i)
{
if( i < 6 )
{
printf("Failed!\n");
}
else if( (6 <= i) && (i <= 8) )
{
printf("Good!\n");
}
else
{
printf("Perfect!\n");
}
}
int main()
{
f1(5); // Failed!
f1(9); // Perfect!
f1(7); // Good!
return 0;
}
输出结果:
Failed!
Perfect!
Good!
¶2、switch 语句分析
- 多用于多分支判断
1)必须要有 break ,否则会导致分支重叠
2)case 语句中的值只能是整形或者字符型
3)按字母或者数字顺序排列各条语句
4)正常的放在前面,异常的放在后面
5)default 必须加上,只用于处理正真异常的情况
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
void f2(char i)
{
switch(i)
{
case 'c':
printf("Compile\n");
break;
case 'd':
printf("Debug\n");
break;
case 'o':
printf("Object\n");
break;
case 'r':
printf("Run\n");
break;
default:
printf("Unknown\n");
break;
}
}
int main()
{
f2('o'); // Object
f2('d'); // Debug
f2('e'); // Unknown
return 0;
}
运行结果:
Object
Debug
Unknown
¶3、循环语句
-
for 先判断,适用于循环次数固定的循环
-
while 先判断,适用于循环次数不固定的场合
-
do while 循环至少执行一次循环体
-
break 和 continue 的区别
break 表示终止循环
continue 表示终止本次循环,进入下次循环
-
do while(0) 巧妙使用,释放内存空间,避开内存泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int test()
{
int *ptr = malloc(...);
do
{
dosomething...;
if(error)
break;
dosomething...;
if(error)
break;
dosomething...;
}
while(0);
free(ptr);
return 0;
}
六、c语言变量属性
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用
- 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
register int j = 0; // 向编译器申请将 j 存储于寄存器中
printf("%p\n", &j); // error
return 0;
}
运行结果:
a.c:7: error: address of register variable ‘j’ requested
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区
- 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int f1()
{
int r = 0;
r++;
return r;
}
int f2()
{
static int r = 0;
r++;
return r;
}
int main()
{
auto int i = 0; // 显示声明 auto 属性,i 为栈变量
static int k = 0; // 局部变量 k 的存储区位于静态区,作用域位于 main 中
printf("&i = %p\n", &i);
printf("&j = %p\n", &k);
for(i=0; i<5; i++)
{
printf("%d\n", f1()); // 1,1,1,1,1
}
printf("\n");
for(i=0; i<5; i++)
{
printf("%d\n", f2()); // 1,2,3,4,5
}
return 0;
}
运行结果:
&i = 0xbfa141cc
&k = 0x804a020
1
1
1
1
1
1
2
3
4
5
编程实验2,修饰全局变量
1
2
3
4
5
6
7
8
9
//头文件 a.h
static int g_i;
static int g_j;
int getI() //使用是这个方式获得static声明的全局变量
{
return g_i;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//c文件
extern int getI();
extern int g_j;
int main()
{
printf("%d\n", g_j); // ERROR
printf("%d\n", getI()); // 0
return 0;
}
运行结果:
5-2.c:(.text+0xb): undefined reference to `g_j'
说明:
注释掉 printf("%d\n", g_j);正常运行输出 0
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
extern int i;
printf("i = %d\n",i);
return 0;
}
int i = 1;
运行结果:
i = 1
- “告诉”c++编译器用c方式编译
1
2
3
4
5
6
7
8
extern "C"
{
/*...*/
}
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void func(int n)
{
int* p = NULL;
if(n < 0)
{
goto STATUS;
}
p = (int*)malloc(sizeof(int)*n);
STATUS:
p[0] = n;
free(p);
}
int main(int argv, char* argc[])
{
printf("begin ...\n");
printf("func(1)\n");
func(1); // 正常运行
printf("func(-1)\n");
func(-1); // 内核崩溃
printf("end\n");
return 0;
}
运行结果:
begin ...
func(1)
func(-1)
Segmentation fault (core dumped)
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
const int g_cc = 2;
int main()
{
const int cc = 1;
int* p = (int*)&cc;
printf("cc = %d\n", cc); // cc = 1
*p = 3;
printf("cc = %d\n", cc); // cc = 3
p = (int*)&g_cc;
printf("g_cc = %d\n", g_cc); // g_cc = 2
*p = 4; // error
printf("g_cc = %d\n", g_cc);
return 0;
}
运行结果:
cc = 1
cc = 3
g_cc = 2
段错误
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1
const char* s = ”hello word”; //字符串字面量
¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、有符号数
- 声明
默认为有符号数,用 signed 关键字声明 - 数据类型的最高位用来标识数据的符号
最高位为1表示这个数为负数
最高位为0表示这个数为正数 - 有符号数的表示方法:在计算机内部用补码表示有符号数
正数的补码为正数本身
负数的补码为对应的正数的反码加1
¶2、无符号数
- 声明
用 unsigned 关键字声明,不能声明浮点型 float double - 特点
默认为正数
没有符号位
最大值 + 1 = 最小值
最小值 - 1 = 最大值
有符号数与无符号整形数(unsigned int)混合运算,有符号会被转换为无符号数,结果为无符号数
¶3、编程实验
¶编程实验1:证明有符号数的表示方法
1 |
|
¶编程实验2:有符号数与无符号数的混合运算
1 |
|
¶编程实验3:无符号数(最小值 - 1 = 最大值)
1 |
|
三、内存中的浮点数(float double)
¶1、存储方式
符号位,指数,尾数
存储表
类型
符号
指数
尾数
float
1位(第31位)
8位(第23-30位)
23位(第0-22位)
double
1位(第63位)
11位(第52-62位)
52位(第0-51位)
¶2、浮点数转换(十进制)
1)将浮点数转换为二进制
2)用科学计数法表示二进制浮点数
3)计算指数偏移后的值 (指数+偏移量)
4)偏移量: float 127
double 1023
¶3、8.25的float的表示
- 转换为二进制数
8.25 ==> 1000.01
- 用科学计数法表示二进制浮点数
100.01 ==> 1.00001 *2^3
- 计算指数偏移后的值
3 + 127 = 130 ==> 1000 0010
- 小数部分
00001
- 内存中的表示
0x41040000
0(符号) 1000 0010(指数) 00001 0000000000000000(小数)
- 补充知识点:
十进制小数转为二进制小数(乘2取整)
例子:0.25
0.25 x 2 = 0.5 取整是0
0.5 x 2 = 1.0 取整是1
即 0.25 的二进制表示方法为 0.01
¶4、浮点型的秘密(重点)
-
float可以表示的具体数值个数与int类型相同
-
flaot可表示的数字之间是不连续的,存在间隙
-
float只是一种近似的表示法,不能作为精确数使用
-
float的运算速度比int慢的多
¶5、编程实验
¶编程实验1:8.25 float的表示
1
2
3
4
5
6
7
8
9
10
11
12
13
int main(int argv, char* argc[])
{
float f = 8.25;
unsigned int* p = (unsigned int*)&f;
printf("0x%x\n", *p);
return 0;
}
运行结果:0x41040000
¶编程实验2:float 类型的不精确性,与不连续性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main(int argv, char* argc[])
{
float f = 3.14;
float f1 = 123456789;
printf("f = %0.10f\n", f);
printf("f1 = %0.10f\n", f1);
return 0;
}
运行结果:
f = 3.1400001049
f1 = 123456792.0000000000
四、数据类型之间的转换
¶1、强制类型转换
(type)var_name
(type)vale
转换结果:
1)目标类型能够容纳目标值:结果不变
2)目标类型不能容纳目标值:结果将产生截断保留低位丢掉高位
例:float转换为 int ,直接丢掉小数部分
3)不是所有的强制类型转换都能成功,不能转换编译器报错
例:结构体转换为 int 类型
¶2、隐式类型转换
编译器主动进行的转换
低类型:占用字节数相对较小的变量
高类型:占用字节数相对较高的变量
1)转换的安全性
a)低类型到高类型的转换时是安全的,不会产生截断
b)高类型到低类型的转换时是不安全的,会产生截断,产生不正确的结果
2)转换发生点:
a)算数运算,低类型转换为高类型
b)赋值表达式中,表达式中的右值类型转换为左值的类型
c)函数调用时,形参转换为实参的类型
d)函数返回值,return表达式后面的返回值转换为返回值类型
¶3、编程实验
¶编程实验1:强制类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
typedef struct tag_ts
{
int i;
int j;
}TS;
TS ts;
int main(int argv, char* argc[])
{
short s = 0x1122;
char c = (char)s; // 0x22
int i = (int)s; // 0x1122
int j = (int)3.123; // 3
unsigned int p = (unsigned int)&ts; // 64位机器产生截断,32位机器正常转换
// long l = (long)ts; // 转换失败编译报错
// ts = (TS)s; // 转换失败编译报错
printf("c = 0x%x\n", c);
printf("i = 0x%x\n", i);
printf("j = 0x%x\n", j);
printf("p = 0x%x\n", p);
return 0;
}
运行结果:
c = 0x22
i = 0x1122
j = 0x3
p = 0x3558018
¶编程实验2:隐式类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int main(int argv, char* argc[])
{
char c = 'a';
int i = c;
unsigned int j = 0x11223344;
short s = j;
printf("c = %c\n", c); // a
printf("i = %d\n", i); // 97
printf("j = 0x%x\n", j); // 0x11223344
printf("s = 0x%x\n", s); // 0x3344
printf("sizeof(c+s):%ld\n", sizeof(c+s)); // 4
return 0;
}
运行结果
c = a
i = 97
j = 0x11223344
s = 0x3344
sizeof(c+s):4
五、分支语句
¶1、if 语句分析
- 多用于复杂逻辑进行判断
- 与零值比较注意点
1)bool 型变量应该直接出现在条件中,不要进行比较
2)变量和 0 字面常量比较,0 字面常量应该出现在比较符的左边
3)float 不能直接和 0 进行比较,需要定义精度
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void f1(int i)
{
if( i < 6 )
{
printf("Failed!\n");
}
else if( (6 <= i) && (i <= 8) )
{
printf("Good!\n");
}
else
{
printf("Perfect!\n");
}
}
int main()
{
f1(5); // Failed!
f1(9); // Perfect!
f1(7); // Good!
return 0;
}
输出结果:
Failed!
Perfect!
Good!
¶2、switch 语句分析
- 多用于多分支判断
1)必须要有 break ,否则会导致分支重叠
2)case 语句中的值只能是整形或者字符型
3)按字母或者数字顺序排列各条语句
4)正常的放在前面,异常的放在后面
5)default 必须加上,只用于处理正真异常的情况
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
void f2(char i)
{
switch(i)
{
case 'c':
printf("Compile\n");
break;
case 'd':
printf("Debug\n");
break;
case 'o':
printf("Object\n");
break;
case 'r':
printf("Run\n");
break;
default:
printf("Unknown\n");
break;
}
}
int main()
{
f2('o'); // Object
f2('d'); // Debug
f2('e'); // Unknown
return 0;
}
运行结果:
Object
Debug
Unknown
¶3、循环语句
-
for 先判断,适用于循环次数固定的循环
-
while 先判断,适用于循环次数不固定的场合
-
do while 循环至少执行一次循环体
-
break 和 continue 的区别
break 表示终止循环
continue 表示终止本次循环,进入下次循环
-
do while(0) 巧妙使用,释放内存空间,避开内存泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int test()
{
int *ptr = malloc(...);
do
{
dosomething...;
if(error)
break;
dosomething...;
if(error)
break;
dosomething...;
}
while(0);
free(ptr);
return 0;
}
六、c语言变量属性
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用
- 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
register int j = 0; // 向编译器申请将 j 存储于寄存器中
printf("%p\n", &j); // error
return 0;
}
运行结果:
a.c:7: error: address of register variable ‘j’ requested
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区
- 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int f1()
{
int r = 0;
r++;
return r;
}
int f2()
{
static int r = 0;
r++;
return r;
}
int main()
{
auto int i = 0; // 显示声明 auto 属性,i 为栈变量
static int k = 0; // 局部变量 k 的存储区位于静态区,作用域位于 main 中
printf("&i = %p\n", &i);
printf("&j = %p\n", &k);
for(i=0; i<5; i++)
{
printf("%d\n", f1()); // 1,1,1,1,1
}
printf("\n");
for(i=0; i<5; i++)
{
printf("%d\n", f2()); // 1,2,3,4,5
}
return 0;
}
运行结果:
&i = 0xbfa141cc
&k = 0x804a020
1
1
1
1
1
1
2
3
4
5
编程实验2,修饰全局变量
1
2
3
4
5
6
7
8
9
//头文件 a.h
static int g_i;
static int g_j;
int getI() //使用是这个方式获得static声明的全局变量
{
return g_i;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//c文件
extern int getI();
extern int g_j;
int main()
{
printf("%d\n", g_j); // ERROR
printf("%d\n", getI()); // 0
return 0;
}
运行结果:
5-2.c:(.text+0xb): undefined reference to `g_j'
说明:
注释掉 printf("%d\n", g_j);正常运行输出 0
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
extern int i;
printf("i = %d\n",i);
return 0;
}
int i = 1;
运行结果:
i = 1
- “告诉”c++编译器用c方式编译
1
2
3
4
5
6
7
8
extern "C"
{
/*...*/
}
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void func(int n)
{
int* p = NULL;
if(n < 0)
{
goto STATUS;
}
p = (int*)malloc(sizeof(int)*n);
STATUS:
p[0] = n;
free(p);
}
int main(int argv, char* argc[])
{
printf("begin ...\n");
printf("func(1)\n");
func(1); // 正常运行
printf("func(-1)\n");
func(-1); // 内核崩溃
printf("end\n");
return 0;
}
运行结果:
begin ...
func(1)
func(-1)
Segmentation fault (core dumped)
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
const int g_cc = 2;
int main()
{
const int cc = 1;
int* p = (int*)&cc;
printf("cc = %d\n", cc); // cc = 1
*p = 3;
printf("cc = %d\n", cc); // cc = 3
p = (int*)&g_cc;
printf("g_cc = %d\n", g_cc); // g_cc = 2
*p = 4; // error
printf("g_cc = %d\n", g_cc);
return 0;
}
运行结果:
cc = 1
cc = 3
g_cc = 2
段错误
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1
const char* s = ”hello word”; //字符串字面量
¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、存储方式
符号位,指数,尾数
| 存储表 | |||
|---|---|---|---|
| 类型 | 符号 | 指数 | 尾数 |
| float | 1位(第31位) | 8位(第23-30位) | 23位(第0-22位) |
| double | 1位(第63位) | 11位(第52-62位) | 52位(第0-51位) |
¶2、浮点数转换(十进制)
1)将浮点数转换为二进制
2)用科学计数法表示二进制浮点数
3)计算指数偏移后的值 (指数+偏移量)
4)偏移量: float 127
double 1023
¶3、8.25的float的表示
- 转换为二进制数
8.25 ==> 1000.01 - 用科学计数法表示二进制浮点数
100.01 ==> 1.00001 *2^3 - 计算指数偏移后的值
3 + 127 = 130 ==> 1000 0010 - 小数部分
00001 - 内存中的表示
0x41040000
0(符号) 1000 0010(指数) 00001 0000000000000000(小数) - 补充知识点:
十进制小数转为二进制小数(乘2取整)
例子:0.25
0.25 x 2 = 0.5 取整是0
0.5 x 2 = 1.0 取整是1
即 0.25 的二进制表示方法为 0.01
¶4、浮点型的秘密(重点)
-
float可以表示的具体数值个数与int类型相同
-
flaot可表示的数字之间是不连续的,存在间隙
-
float只是一种近似的表示法,不能作为精确数使用
-
float的运算速度比int慢的多
¶5、编程实验
¶编程实验1:8.25 float的表示
1 |
|
¶编程实验2:float 类型的不精确性,与不连续性
1 |
|
四、数据类型之间的转换
¶1、强制类型转换
(type)var_name
(type)vale
转换结果:
1)目标类型能够容纳目标值:结果不变
2)目标类型不能容纳目标值:结果将产生截断保留低位丢掉高位
例:float转换为 int ,直接丢掉小数部分
3)不是所有的强制类型转换都能成功,不能转换编译器报错
例:结构体转换为 int 类型
¶2、隐式类型转换
编译器主动进行的转换
低类型:占用字节数相对较小的变量
高类型:占用字节数相对较高的变量
1)转换的安全性
a)低类型到高类型的转换时是安全的,不会产生截断
b)高类型到低类型的转换时是不安全的,会产生截断,产生不正确的结果
2)转换发生点:
a)算数运算,低类型转换为高类型
b)赋值表达式中,表达式中的右值类型转换为左值的类型
c)函数调用时,形参转换为实参的类型
d)函数返回值,return表达式后面的返回值转换为返回值类型
¶3、编程实验
¶编程实验1:强制类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
typedef struct tag_ts
{
int i;
int j;
}TS;
TS ts;
int main(int argv, char* argc[])
{
short s = 0x1122;
char c = (char)s; // 0x22
int i = (int)s; // 0x1122
int j = (int)3.123; // 3
unsigned int p = (unsigned int)&ts; // 64位机器产生截断,32位机器正常转换
// long l = (long)ts; // 转换失败编译报错
// ts = (TS)s; // 转换失败编译报错
printf("c = 0x%x\n", c);
printf("i = 0x%x\n", i);
printf("j = 0x%x\n", j);
printf("p = 0x%x\n", p);
return 0;
}
运行结果:
c = 0x22
i = 0x1122
j = 0x3
p = 0x3558018
¶编程实验2:隐式类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int main(int argv, char* argc[])
{
char c = 'a';
int i = c;
unsigned int j = 0x11223344;
short s = j;
printf("c = %c\n", c); // a
printf("i = %d\n", i); // 97
printf("j = 0x%x\n", j); // 0x11223344
printf("s = 0x%x\n", s); // 0x3344
printf("sizeof(c+s):%ld\n", sizeof(c+s)); // 4
return 0;
}
运行结果
c = a
i = 97
j = 0x11223344
s = 0x3344
sizeof(c+s):4
五、分支语句
¶1、if 语句分析
- 多用于复杂逻辑进行判断
- 与零值比较注意点
1)bool 型变量应该直接出现在条件中,不要进行比较
2)变量和 0 字面常量比较,0 字面常量应该出现在比较符的左边
3)float 不能直接和 0 进行比较,需要定义精度
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void f1(int i)
{
if( i < 6 )
{
printf("Failed!\n");
}
else if( (6 <= i) && (i <= 8) )
{
printf("Good!\n");
}
else
{
printf("Perfect!\n");
}
}
int main()
{
f1(5); // Failed!
f1(9); // Perfect!
f1(7); // Good!
return 0;
}
输出结果:
Failed!
Perfect!
Good!
¶2、switch 语句分析
- 多用于多分支判断
1)必须要有 break ,否则会导致分支重叠
2)case 语句中的值只能是整形或者字符型
3)按字母或者数字顺序排列各条语句
4)正常的放在前面,异常的放在后面
5)default 必须加上,只用于处理正真异常的情况
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
void f2(char i)
{
switch(i)
{
case 'c':
printf("Compile\n");
break;
case 'd':
printf("Debug\n");
break;
case 'o':
printf("Object\n");
break;
case 'r':
printf("Run\n");
break;
default:
printf("Unknown\n");
break;
}
}
int main()
{
f2('o'); // Object
f2('d'); // Debug
f2('e'); // Unknown
return 0;
}
运行结果:
Object
Debug
Unknown
¶3、循环语句
-
for 先判断,适用于循环次数固定的循环
-
while 先判断,适用于循环次数不固定的场合
-
do while 循环至少执行一次循环体
-
break 和 continue 的区别
break 表示终止循环
continue 表示终止本次循环,进入下次循环
-
do while(0) 巧妙使用,释放内存空间,避开内存泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int test()
{
int *ptr = malloc(...);
do
{
dosomething...;
if(error)
break;
dosomething...;
if(error)
break;
dosomething...;
}
while(0);
free(ptr);
return 0;
}
六、c语言变量属性
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用
- 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
register int j = 0; // 向编译器申请将 j 存储于寄存器中
printf("%p\n", &j); // error
return 0;
}
运行结果:
a.c:7: error: address of register variable ‘j’ requested
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区
- 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int f1()
{
int r = 0;
r++;
return r;
}
int f2()
{
static int r = 0;
r++;
return r;
}
int main()
{
auto int i = 0; // 显示声明 auto 属性,i 为栈变量
static int k = 0; // 局部变量 k 的存储区位于静态区,作用域位于 main 中
printf("&i = %p\n", &i);
printf("&j = %p\n", &k);
for(i=0; i<5; i++)
{
printf("%d\n", f1()); // 1,1,1,1,1
}
printf("\n");
for(i=0; i<5; i++)
{
printf("%d\n", f2()); // 1,2,3,4,5
}
return 0;
}
运行结果:
&i = 0xbfa141cc
&k = 0x804a020
1
1
1
1
1
1
2
3
4
5
编程实验2,修饰全局变量
1
2
3
4
5
6
7
8
9
//头文件 a.h
static int g_i;
static int g_j;
int getI() //使用是这个方式获得static声明的全局变量
{
return g_i;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//c文件
extern int getI();
extern int g_j;
int main()
{
printf("%d\n", g_j); // ERROR
printf("%d\n", getI()); // 0
return 0;
}
运行结果:
5-2.c:(.text+0xb): undefined reference to `g_j'
说明:
注释掉 printf("%d\n", g_j);正常运行输出 0
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
extern int i;
printf("i = %d\n",i);
return 0;
}
int i = 1;
运行结果:
i = 1
- “告诉”c++编译器用c方式编译
1
2
3
4
5
6
7
8
extern "C"
{
/*...*/
}
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void func(int n)
{
int* p = NULL;
if(n < 0)
{
goto STATUS;
}
p = (int*)malloc(sizeof(int)*n);
STATUS:
p[0] = n;
free(p);
}
int main(int argv, char* argc[])
{
printf("begin ...\n");
printf("func(1)\n");
func(1); // 正常运行
printf("func(-1)\n");
func(-1); // 内核崩溃
printf("end\n");
return 0;
}
运行结果:
begin ...
func(1)
func(-1)
Segmentation fault (core dumped)
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
const int g_cc = 2;
int main()
{
const int cc = 1;
int* p = (int*)&cc;
printf("cc = %d\n", cc); // cc = 1
*p = 3;
printf("cc = %d\n", cc); // cc = 3
p = (int*)&g_cc;
printf("g_cc = %d\n", g_cc); // g_cc = 2
*p = 4; // error
printf("g_cc = %d\n", g_cc);
return 0;
}
运行结果:
cc = 1
cc = 3
g_cc = 2
段错误
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1
const char* s = ”hello word”; //字符串字面量
¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、强制类型转换
(type)var_name
(type)vale
转换结果:
1)目标类型能够容纳目标值:结果不变
2)目标类型不能容纳目标值:结果将产生截断保留低位丢掉高位
例:float转换为 int ,直接丢掉小数部分
3)不是所有的强制类型转换都能成功,不能转换编译器报错
例:结构体转换为 int 类型
¶2、隐式类型转换
编译器主动进行的转换
低类型:占用字节数相对较小的变量
高类型:占用字节数相对较高的变量
1)转换的安全性
a)低类型到高类型的转换时是安全的,不会产生截断
b)高类型到低类型的转换时是不安全的,会产生截断,产生不正确的结果
2)转换发生点:
a)算数运算,低类型转换为高类型
b)赋值表达式中,表达式中的右值类型转换为左值的类型
c)函数调用时,形参转换为实参的类型
d)函数返回值,return表达式后面的返回值转换为返回值类型
¶3、编程实验
¶编程实验1:强制类型转换
1 |
|
¶编程实验2:隐式类型转换
1 |
|
五、分支语句
¶1、if 语句分析
- 多用于复杂逻辑进行判断
- 与零值比较注意点
1)bool 型变量应该直接出现在条件中,不要进行比较
2)变量和 0 字面常量比较,0 字面常量应该出现在比较符的左边
3)float 不能直接和 0 进行比较,需要定义精度
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void f1(int i)
{
if( i < 6 )
{
printf("Failed!\n");
}
else if( (6 <= i) && (i <= 8) )
{
printf("Good!\n");
}
else
{
printf("Perfect!\n");
}
}
int main()
{
f1(5); // Failed!
f1(9); // Perfect!
f1(7); // Good!
return 0;
}
输出结果:
Failed!
Perfect!
Good!
¶2、switch 语句分析
- 多用于多分支判断
1)必须要有 break ,否则会导致分支重叠
2)case 语句中的值只能是整形或者字符型
3)按字母或者数字顺序排列各条语句
4)正常的放在前面,异常的放在后面
5)default 必须加上,只用于处理正真异常的情况
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
void f2(char i)
{
switch(i)
{
case 'c':
printf("Compile\n");
break;
case 'd':
printf("Debug\n");
break;
case 'o':
printf("Object\n");
break;
case 'r':
printf("Run\n");
break;
default:
printf("Unknown\n");
break;
}
}
int main()
{
f2('o'); // Object
f2('d'); // Debug
f2('e'); // Unknown
return 0;
}
运行结果:
Object
Debug
Unknown
¶3、循环语句
-
for 先判断,适用于循环次数固定的循环
-
while 先判断,适用于循环次数不固定的场合
-
do while 循环至少执行一次循环体
-
break 和 continue 的区别
break 表示终止循环
continue 表示终止本次循环,进入下次循环
-
do while(0) 巧妙使用,释放内存空间,避开内存泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int test()
{
int *ptr = malloc(...);
do
{
dosomething...;
if(error)
break;
dosomething...;
if(error)
break;
dosomething...;
}
while(0);
free(ptr);
return 0;
}
六、c语言变量属性
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用
- 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
register int j = 0; // 向编译器申请将 j 存储于寄存器中
printf("%p\n", &j); // error
return 0;
}
运行结果:
a.c:7: error: address of register variable ‘j’ requested
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区
- 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int f1()
{
int r = 0;
r++;
return r;
}
int f2()
{
static int r = 0;
r++;
return r;
}
int main()
{
auto int i = 0; // 显示声明 auto 属性,i 为栈变量
static int k = 0; // 局部变量 k 的存储区位于静态区,作用域位于 main 中
printf("&i = %p\n", &i);
printf("&j = %p\n", &k);
for(i=0; i<5; i++)
{
printf("%d\n", f1()); // 1,1,1,1,1
}
printf("\n");
for(i=0; i<5; i++)
{
printf("%d\n", f2()); // 1,2,3,4,5
}
return 0;
}
运行结果:
&i = 0xbfa141cc
&k = 0x804a020
1
1
1
1
1
1
2
3
4
5
编程实验2,修饰全局变量
1
2
3
4
5
6
7
8
9
//头文件 a.h
static int g_i;
static int g_j;
int getI() //使用是这个方式获得static声明的全局变量
{
return g_i;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//c文件
extern int getI();
extern int g_j;
int main()
{
printf("%d\n", g_j); // ERROR
printf("%d\n", getI()); // 0
return 0;
}
运行结果:
5-2.c:(.text+0xb): undefined reference to `g_j'
说明:
注释掉 printf("%d\n", g_j);正常运行输出 0
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
extern int i;
printf("i = %d\n",i);
return 0;
}
int i = 1;
运行结果:
i = 1
- “告诉”c++编译器用c方式编译
1
2
3
4
5
6
7
8
extern "C"
{
/*...*/
}
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void func(int n)
{
int* p = NULL;
if(n < 0)
{
goto STATUS;
}
p = (int*)malloc(sizeof(int)*n);
STATUS:
p[0] = n;
free(p);
}
int main(int argv, char* argc[])
{
printf("begin ...\n");
printf("func(1)\n");
func(1); // 正常运行
printf("func(-1)\n");
func(-1); // 内核崩溃
printf("end\n");
return 0;
}
运行结果:
begin ...
func(1)
func(-1)
Segmentation fault (core dumped)
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
const int g_cc = 2;
int main()
{
const int cc = 1;
int* p = (int*)&cc;
printf("cc = %d\n", cc); // cc = 1
*p = 3;
printf("cc = %d\n", cc); // cc = 3
p = (int*)&g_cc;
printf("g_cc = %d\n", g_cc); // g_cc = 2
*p = 4; // error
printf("g_cc = %d\n", g_cc);
return 0;
}
运行结果:
cc = 1
cc = 3
g_cc = 2
段错误
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1
const char* s = ”hello word”; //字符串字面量
¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、if 语句分析
- 多用于复杂逻辑进行判断
- 与零值比较注意点
1)bool 型变量应该直接出现在条件中,不要进行比较
2)变量和 0 字面常量比较,0 字面常量应该出现在比较符的左边
3)float 不能直接和 0 进行比较,需要定义精度
编程实验
1 |
|
¶2、switch 语句分析
- 多用于多分支判断
1)必须要有 break ,否则会导致分支重叠
2)case 语句中的值只能是整形或者字符型
3)按字母或者数字顺序排列各条语句
4)正常的放在前面,异常的放在后面
5)default 必须加上,只用于处理正真异常的情况
编程实验
1 |
|
¶3、循环语句
-
for 先判断,适用于循环次数固定的循环
-
while 先判断,适用于循环次数不固定的场合
-
do while 循环至少执行一次循环体
-
break 和 continue 的区别
break 表示终止循环
continue 表示终止本次循环,进入下次循环 -
do while(0) 巧妙使用,释放内存空间,避开内存泄漏
1 | int test() |
六、c语言变量属性
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用
- 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
register int j = 0; // 向编译器申请将 j 存储于寄存器中
printf("%p\n", &j); // error
return 0;
}
运行结果:
a.c:7: error: address of register variable ‘j’ requested
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区
- 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int f1()
{
int r = 0;
r++;
return r;
}
int f2()
{
static int r = 0;
r++;
return r;
}
int main()
{
auto int i = 0; // 显示声明 auto 属性,i 为栈变量
static int k = 0; // 局部变量 k 的存储区位于静态区,作用域位于 main 中
printf("&i = %p\n", &i);
printf("&j = %p\n", &k);
for(i=0; i<5; i++)
{
printf("%d\n", f1()); // 1,1,1,1,1
}
printf("\n");
for(i=0; i<5; i++)
{
printf("%d\n", f2()); // 1,2,3,4,5
}
return 0;
}
运行结果:
&i = 0xbfa141cc
&k = 0x804a020
1
1
1
1
1
1
2
3
4
5
编程实验2,修饰全局变量
1
2
3
4
5
6
7
8
9
//头文件 a.h
static int g_i;
static int g_j;
int getI() //使用是这个方式获得static声明的全局变量
{
return g_i;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//c文件
extern int getI();
extern int g_j;
int main()
{
printf("%d\n", g_j); // ERROR
printf("%d\n", getI()); // 0
return 0;
}
运行结果:
5-2.c:(.text+0xb): undefined reference to `g_j'
说明:
注释掉 printf("%d\n", g_j);正常运行输出 0
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
extern int i;
printf("i = %d\n",i);
return 0;
}
int i = 1;
运行结果:
i = 1
- “告诉”c++编译器用c方式编译
1
2
3
4
5
6
7
8
extern "C"
{
/*...*/
}
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void func(int n)
{
int* p = NULL;
if(n < 0)
{
goto STATUS;
}
p = (int*)malloc(sizeof(int)*n);
STATUS:
p[0] = n;
free(p);
}
int main(int argv, char* argc[])
{
printf("begin ...\n");
printf("func(1)\n");
func(1); // 正常运行
printf("func(-1)\n");
func(-1); // 内核崩溃
printf("end\n");
return 0;
}
运行结果:
begin ...
func(1)
func(-1)
Segmentation fault (core dumped)
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
const int g_cc = 2;
int main()
{
const int cc = 1;
int* p = (int*)&cc;
printf("cc = %d\n", cc); // cc = 1
*p = 3;
printf("cc = %d\n", cc); // cc = 3
p = (int*)&g_cc;
printf("g_cc = %d\n", g_cc); // g_cc = 2
*p = 4; // error
printf("g_cc = %d\n", g_cc);
return 0;
}
运行结果:
cc = 1
cc = 3
g_cc = 2
段错误
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1
const char* s = ”hello word”; //字符串字面量
¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、auto 关键字
- C 语言中局部变量的默认属性
- 表明被修饰的变量处于栈上
- 编译器默认所有的局部变量都是 auto
¶2、register 关键字
- 请求编译器将这个局部变量变量存储在寄存器中
1)如果申明具有全局属性的变量则编译器 error
2)cpu 寄存器有限不能长时间占用 - 只是请求寄存器变量,不一定成功
- 变量必须是cpu可以接受的值
- 不能用 & 运算符获取 register 变量的值,否则会报错
存在意义:当时为了解决效率问题,在尽可能需要效率的方,给你效率
编程实验
1 |
|
¶3、static 关键字
- 指明”静态“属性
1) 被修饰的局部变量存储在程序的静态区 - 具有”作用域限定符“作用
1) 修饰的全局变量作用域只是声明文件中
2) 修饰函数的作用域只是声明的文件中
编程实验1,修饰局部变量
1 |
|
编程实验2,修饰全局变量
1 | //头文件 a.h |
1 | //c文件 |
¶4、extern 关键字
- 用于声明“外部”定义的变量或函数
1)变量在文件的其它地方分配空间
2)函数在文件其它地方定义
编程实验
1 |
|
- “告诉”c++编译器用c方式编译
1 |
|
¶5、goto 关键字
- 高手潜规则 禁用 goto
- 项目经验 程序的质量与 goto 出现的次数成反比
- c 语言是一种面向过程的结构性语言(顺序 选择 循环三种结构组合而成),goto 破坏了程序的结构性
编程实验
1 |
|
¶6、const 只读变量
¶1) const 只读变量基本属性
- const 变量是只读的,本质还是变量
- const 修饰的局部变量在栈上分配空间
- const 修饰的全局变量在全局数据区分配空间
- const 只在编译期有用,在运行期无用
注意:
const 不能声明正真意义的常量,它只告诉编译器, const 修饰的变量不能出现在赋值符号的左边即不能只作为左值使用。现代 c 编译器将 const 修饰的具有全局生命的变量(全局变量/静态变量)储存于只读存储区,修改(指针) const 全局变量将导致程序崩溃,标准c语言编译器 const 修饰的全局变量在全局数据区分配空间,其值依然可以修改(指针)
编程实验
1 |
|
¶2) const 变量常用区域
- const 修饰函数参数和函数返回值
- const 修饰函数参数表示在函数体内不希望改变参数的值
- const 修饰函数返回值表示返回值不可改变,多用于返回指针的情形
¶3) 扩展
c 语言中的字符串字面量存储于只读存储区中,在程序中需要使用 const char* 指针
1 | const char* s = ”hello word”; //字符串字面量 |
¶7、volatile 关键字
¶1) 编译器警告指示字
- volatile 关键字告诉编译器每次必须去内存中取变量值
- volatile 关键字主要修饰可能被多个线程访问的变量
- volatile 也可修饰可能被未知因数更改的变量
¶2) 小结
当变量在多线程的程序中被其他线程中改变(内存中的值被改变),或者在中断中被改变(内存中的值被改变),而在线程(中断)外部不会改变变量的值(不从内存中取值),volatile 会降低程序的效率(需要访存)即在需要的时候使用,不需要的不使用,多用于嵌入式驱动开发中,当我们直接访问某个内存地址时需要加上这个关键字。
七、void 的意义
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
f()
{
return 1;
}
int main()
{
f();
f(5);
printf("f() = %d\n",f());
return 0;
}
运行结果:
f() = 1
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* 函数名:MemSet
* 功能说明:设置一片内存的每个字节为相同的数据
*/
void MemSet(void* src, int length, unsigned char n)
{
unsigned char* p = (unsigned char*)src;
int i = 0;
for(i=0; i<length; i++)
{
p[i] = n;
}
}
int main()
{
int a[5] = {1,2,3,4,5};
int i = 0;
MemSet(a, sizeof(a), 0);
for(i=0; i<5; i++)
{
printf("%d\n", a[i]); // 0,0,0,0,0
}
return 0;
}
运行结果:
0
0
0
0
0
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、void 修饰函数参数和返回值
- 如果函数没有返回值,那么应将其申明为 void
- 如果函数没有参数,那么应将其参数申明为 void
- 没有函数返回值类型,默认返回值类型为 int
- 函数 f() 没有参数,f 默认为参数为任意的参数
编程实验
1 |
|
¶2、void 修饰函数返回值和参数是为了表示“无”
- void 为抽象类型(概念上的类型没有大小)
- 不能用于定义变量
- 不能用于定义数组
- 可以定义 void 类型的指针
- 任意的指针都是 4 个或者 8 个字节的指针
知识延伸
ANSIC:标准 c 语言规范,扩展 c 在 ANSIC上进行扩充
gcc 对 void 进行了扩展,void 的大小为 1
¶3、void指针的意义
- c 语言规定只有相同类型的指针才能相互赋值
- void* 指针作为左值用于“接受”任意类型的指针
- void* 指针作为右值使用时需要进行强制类型转换
编程实验,void 的使用*
1 |
|
八、struct 结构体
¶1,定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tag
{
member-list;
}variable-list,*p_tag ;
说明:
struct 结构体关键字
tag 结构体标志
variable-list 定义此结构体时声明的变量
member-list 结构体成员变量
struct tag 结构体的类型
p_tag 定义此结构体时声明的指针
此结构体在声明的时候创建了两个变量,分别是结构体变量 variable-list 和 指向 NULL 的结构体指针 p_tag
typedef struct tag
{
member-list;
}variable-list,*p_tag ;
与不用typedef 的区别
a)variable-list 定义此结构体时声明的结构体类型,等效于 struct tag
b)p_tag 定义此结构体时声明的结构体指针类型,等效于struct tag*
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
struct SoftArray
{
int len;
int array[];
};
struct SoftArray* create_soft_array(int size)
{
struct SoftArray* ret = NULL;
if( size > 0 )
{
ret = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
ret->len = size;
}
return ret;
}
void delete_soft_array(struct SoftArray* sa)
{
free(sa);
}
void func(struct SoftArray* sa)
{
int i = 0;
if( NULL != sa )
{
for(i=0; i<sa->len; i++)
{
sa->array[i] = i + 1;
}
}
}
int main()
{
int i = 0;
struct SoftArray* sa = create_soft_array(10);
func(sa);
for(i=0; i<sa->len; i++)
{
printf("%d ", sa->array[i]);
}
printf("\n");
delete_soft_array(sa);
return 0;
}
输出结果:1 2 3 4 5 6 7 8 9 10
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1,定义与声明
1 | struct tag |
¶2,空结构体
灰色地带,没有对错。实际开发没有人会定义空结构体
gcc 编译器空结构体占用的内存为 0
bcc,vc10.0 编译器不允许空结构体的存在于c语言里面
¶3,结构体与柔性数组
¶1) 柔性数组即大小待定的数组
c语言可以由结构体产生柔性数组
c语言中结构体中当最后一个元素是大小未知的数组时,不占内存空间(结构体中大小未知的数组不能单独存在,或存在多个)
¶2) 柔性数组的使用
编程实验
1 |
|
九、union 联合体
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int system_mode()
{
union SM
{
int i;
char c;
};
union SM sm;
sm.i = 1;
return sm.c;
}
int main()
{
printf("System Mode: %d\n", system_mode()); //返回1小端模式,返回0大端模式
return 0;
}
运行结果:System Mode: 1
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
语法上与 struct 相似 union 只会分配最大成员空间,所有成员共享这个空间
注意: union 的使用受系统大小端的影响
int i = 1;
0x01 0x00 0x00 0x00
——————————————————> 高地址
小端模式 //低地址存储低位数据
int i = 1;
0x00 0x00 0x00 0x01
——————————————————> 高地址
大端模式 //低地址存储高位数据
取地址规则:取值从低地址开始取值
编程实验
1 |
|
运行结果说明 gcc 编译器下的编译环境为小端模式,低地址存放低字节
十、enum 枚举类型
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
enum enu_name
{
val1 = -1,
val2 = 3,
val3,
...
}enum_val,...;
说明:
enum 枚举关键字
enu_name 枚举名
val1 标识符1 = 整型常数-1
val2 标识符1 = 整型常数3
val3 标识符1 = 整型常数4
enum_val 枚举变量
enum enu_name 枚举类型
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
enum 是c语言的一种自定义类型
enum 值是可以根据需要自定义的整型值
¶1、定义与声明
1 | enum enu_name |
注意:
1)枚举中每个成员(标识符)结束符是’,’最后一个可以省略
2)第一个定义未初始化的标识符默认为0
3)初始化可以赋负数
4)连续未赋值的的标识符的值是在前一个标识符的值基础上加1
5)enum 类型的变量只能取定义时的离散值
6)在c语言中可以定义正真意义上的常量
7)本质上枚举类型就是整型
十一、sizeof 关键字
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1
2
3
4
5
示例:
int var = 0;
int size = sizeof(var++);
Printf(“var = %d,size = %d”,var,size);
//输出结果: 0 , 4
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
sizeof 用于计算类型或变量所占内存大小
用于类型 sizeof (type)
用于变量 sizeof (var) 或者 sizeof var
注意:
1)sizeof 是编译器内置指示符(关键字)而不是函数
2)sizeof 在编译期就已经确定,在编译过程中所有的 sizeof 将 被具体的数值所替换,程序的执行过程与 sizeof 没有任何关系
1 | 示例: |
十二、typedef 关键字
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
C语言中用于给已经存在的数据类型重命名
语法: typedef type new_neme;
注意:
1)本质上不能产生新的类型
2)重命名的类型: a)可以在 typedef 语句之后定义; b)不能被 unsigned 和 signed 修饰
注释
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
编译器在编译过程中使用空格替换整个注释
字符串字面量中的//和/…/ 不代表注释符号
/…/不能被嵌套
在编译器看来注释和其他程序元素是平等的
注意:
1)注释是对代码的提示,避免臃肿和喧宾夺主
2)一目了然的代码避免注释
3)不要用缩写来注释代码,这样可能会产生误解
4)注释用于阐述原因和意图而不是描述程序的运行过程
5)注释应该准确易懂,防止二义性,错误的注释有害无利
\ 接续符
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
编译器会将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行
在接续单词时,反斜杠不能有空格,反斜杠下一行也不能有空格
接续符适合在定义宏代码块时使用
\ 转义字符
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
\n 换行回车
\t 横向跳到下一制表位置
\v 竖向挑格
\b 退格
\r 回车,回到行首
\f 走纸换页
\ 反斜杠“\”
' 单引号
\a 呜铃
\ddd 1~3 位8进制数所代表的字符
\xhh 1~2 位16进制数所代表的字符
小结:a) \ 作为接续符使用可以出现在程序中间; b) \ 作为转义字符使用时需出现单引号或者双引号 之间
单引号双引号
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
c语言中的单引号用来表示字符字面量
‘a’占1个字节
‘a’ + 1 代表’a’的ascll码+1 ,结果为’b’
字符字面量被编译为对应的ascll码
c语言中的双引号用来表示字符串字面量
"a"占两个字节
“a” + 1 表示指针运算,结果指向"a"的结束符’/0’
字符串字面量被编译为对应的内存地址
知识拓展
printf的第一个参数被当成字符串内存地址
内存的低地址空间不能在程序中随意访问即小于0x08048000的地址,随意访问会产生段错误
逻辑运算符
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int k = 0;
++i || ++j && ++k; // ==> (true && ++i) || (++j && ++k)
printf("%d\n", i); // 1
printf("%d\n", j); // 0
printf("%d\n", k); // 0
return 0;
}
运行结果:
1
0
0
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
printf("%d\n", !0); // 1
printf("%d\n", !1); // 0
printf("%d\n", !100); // 0
printf("%d\n", !-1000); // 0
return 0;
}
运行结果:
1
0
0
0
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、逻辑||和&&
程序中的短路
||从左向右开始计算:(或)
当遇到为真的条件时停止计算,整个表达式为真
所有条件为假时表达式才为假
&&从左到右开始计算:(且)
当遇到为假的条件时停止计算,整个表达式为假
所有条件为真时表达式才为真
编程实验
1 | #include <stdio.h> |
¶2、逻辑 !
!0 返回1
!非0 返回0
编程实验
1 | #include <stdio.h> |
位运算符分析
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
int main()
{
printf("%d\n", 3 << 2); //12
printf("%d\n", 3 >> 1); //1
printf("%d\n", -1 >> 1); //-1
printf("%d\n", 0x01 << 2 + 3); //32
printf("%d\n", 3 << -1); // oops!
return 0;
}
运行结果:
12
1
-1
32
1
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1
2
3
unsigned char a;
a &= ~(1<<3); //将该位清零
a |= 1<<3; //将该为置位
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1
2
3
unsigned char a;
a &= ~(3<<3); //将该位清零
a |= 3<<3; //将该为置位
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
c语言中的位运算符
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 左移
>> 右移
¶1、左移右移
1)左移
左移运算符 << 将运算数的二进位左移
规则:高位丢弃,低位补0
移动一次相当于相当于乘2,运算效率更高
2)右移
右移运算符 >> 把运算数的二进制数右移
规则:高位补符号位,低位丢弃
移动一次相当于除二,运算效率更高
正数:有余舍弃
负数:有余进位
编程实验
1 | #include <stdio.h> |
注意:
1)左操作数必须为整数类型
2)char 和 short 被隐式类型转换为了 int 后进行位移操作
3)右操作数的范围必须为[0,31],如果操作数的值超出范围,则根据编译器的不同而不同,不能得到准确结果
扩充:
四则算符的优先级高于位运算符,容易出错
防错措施: 1)尽量避免位运算符,逻辑运算符,和数学运算符出现在同一个表达式中;2)需要时,尽量使用括号来表达运算次序
¶2、位运算与逻辑运算的不同
位运算没有短路规则,每个操作数都参与运算
位运算结果为整数,而不是0或1
位运算优先级高于逻辑运算
¶3、常用技巧
1.操作一任意一个数据位,将一个char数据中的第三位置位
1 | unsigned char a; |
2.操作一任意一个数据位,将一个int数据中的第3,4位置位
1 | unsigned char a; |
运算优先级: 四则运算>位运算>逻辑运算
++、- -操作符的本质
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i);
printf("r = %d\n", r);
r = (++i) + (++i) + (++i);
printf("i = %d\n", i);
printf("r = %d\n", r);
return 0;
}
gcc运行结果:
i = 3
r = 0
i = 6
r = 16
vs2010运行结果:
i = 3
r = 0
i = 6
r = 18
java运行结果:
i = 3
r = 3
i = 6
r = 15
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i+++i+++i;//根据贪心发编译器读入++i++后才运算,==》1++ ==》ERROR
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b /*p; //根据贪心法,读入b/*之后便认为/*为注释符号,后面的内容全部为注释
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
运行结果:
5-2.c:6: error: lvalue required as increment operand
5-2.c:14: error: unterminated comment
5-2.c:14: error: expected ‘;’ at end of input
5-2.c:14: error: expected declaration or statement at end of input
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include<stdio.h>
int main()
{
int i = 0;
int j = ++i + ++i + ++i;
int a = 1;
int b = 4;
int c = a+++b;
int* p = &a;
b = b / *p;
printf("i = %d\n", i);
printf("j = %d\n", j);
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("c = %d\n", c);
return 0;
}
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、基本规则
前置:变量自增(减),取变量值
后置:取变量值,变量自增(减)
编程实验
1 | #include <stdio.h> |
C语言中只规定了++和—对应指令的相对执行顺序
++和—对应的汇编指令不一定连续运行
在混合运算中,++和—的汇编指令可能被打断执行
++和—参与混合运算结果是不确定的
¶2、贪心法:++、- -表达式的阅读技巧
编译器处理的每个符号应尽可能的多包含字符
编译器以从左向右的顺序一个一个尽可能多的读入字符
当读入的字符不可能和已读入的字符组成合法符号为止
编程实验
1 | #include<stdio.h> |
空格可以作为c语言中一个完整的休止符
编译器读入空格后立即对之前读入的符号进行处理
编程实验,修改上面代码使它运行通过
1 | #include<stdio.h> |
三目运算符(a?b:c)
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int m = 0;
char c = 0;
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
m = a < b ? a : b; // m = a ==> m = 1
(a < b ? a : b) = 3; // error
printf("%d\n", a); // 1
printf("%d\n", b); // 2
printf("%d\n\n", m); // 1
printf( "%d\n", sizeof(c ? c : s) ); // 2
printf( "%d\n", sizeof(i ? i : d) ); // 8
printf( "%d\n", sizeof(d ? d : p) ); // error
return 0;
}
运行结果:
5-2.c:18: error: lvalue required as left operand of assignment
5-2.c:26: error: type mismatch in conditional expression
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
可以作为逻辑运算的载体(为if条件句的简化形式)
规则
当a为真的时,返回b的值;否则返回c的值
三目运算符(a?b:c)的返回类型
1)通过隐式类型转换规则返回b和c中较高的类型
2)当b和c不能隐式类型转换到同一类型将出错
编程实验
1 | #include <stdio.h> |
,逗号表达式
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
#include <assert.h>
int strlen(const char* s)
{
return assert(s), (*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("len = %d\n", strlen("Delphi"));
printf("len = %d\n", strlen(NULL));
return 0;
}
运行结果:
len = 6
a.out: 5-2.c:6: strlen: Assertion `s' failed.
已放弃
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
用于将多个式子连接为一个表达式
逗号表达式的值为最后一个表达式的值
逗号表达式中前 N-1 表达式的值可以没有返回值
逗号表达式按照从左向右的顺序计算每个表达式的值:exp1,exp2,exp3,exp4…expN
编程实验,使用逗号表达式检查输入指针的合法性
1 | #include <stdio.h> |
编译过程
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
编译器的组成:预处理器,编译器,汇编器,链接器
¶1、预编译
处理所有的注释
将所有的#define删除,并且展开所有的宏定义
处理条件预编译指令 #if,#ifdef,#elseif,#else,#endif
处理#inlude,展开被包含的文件
保留编译器需要使用的#pragma指令
linux预处理指令示例:
gcc -E a.c -o a.i
¶2、编译
对于处理文件进行 词法分析,语法分析,和语义分析
a,词法分析:分析关键字,标识符,立即数是否合法
b,语法分析:分析表达式是否遵循语法规则
c,语义分析:在语法分析的基础上进一步分析表达式是否合法
d,分析结束后进行代码优化生成相应的汇编代码文件
linux编译指令示例:
gcc -S a.c -o a.s
¶3、汇编
汇编将源代码转变为机器可执行的二进制语言
每条汇编代码语句几乎都对应一条机器指令
linux汇编指令示例:
gcc -c a.c -o a.o
¶4、链接
静态链接
a)目标文件直接进入可执行程序
b)由链接器在链接时将库的内容直接加入到可执行程序中
c)Linux 下静态库的创建和使用
i)编译静态库源码: gcc -c a.c -o a.o
ii)生成静态库文件: ar -q a.a a.o
iii)使用静态库编译:gcc main.c a.a -o main.out
动态链接
a)在程序启动后才加载目标文件
i)可执行程序运行时才动态加载库进行链接
ii)库的内容不会进入可执行程序中
b)Linux 下动态库的创建和使用
编译动态库源码:gcc -shares a.c -o a.so
使用动态库编译:gcc a.c -ldl -o a.out
知识扩展:关键系统调用
dlopen: 打开动态库文件
dlsym: 查找动态库中的函数并返回调用地址
dlclose: 关闭动态库文件
程序中的宏定义#define
¶1、语法
1)简单宏定义
1
#define 宏名 替换文本
2)带参宏定义
1
#define 宏名(参数表) 宏体
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG(s) printf("[%s] {%s:%d} %s \n", __DATE__, __FILE__, __LINE__, s)
int main()
{
int i = 0;
int* p = MALLOC(int, 5);
LOG("Begin to run main code...");
for(i=0; i<5; i++)
{
p[i] = i+1;
}
for(i=0; i<5; i++)
{
printf("%d\n", p[i]);
}
FREE(p);
LOG("End");
return 0;
}
运行结果:
[Aug 13 2019] {5-2.c:15} Begin to run main code...
1
2
3
4
5
[Aug 13 2019] {5-2.c:29} End
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、语法
1)简单宏定义
1 | #define 宏名 替换文本 |
2)带参宏定义
1 | #define 宏名(参数表) 宏体 |
¶2、特点
1) 是预处理器的单元的实体之一
2) 定义的宏可以出现在程序中的任意位置
3) 定义的宏常量可以直接使用
4) 定义之后的代码都可以使用这个宏,没有作用域
5) 定义宏常量本质为字面量,不占内存空间
6) #define 表达式的使用类似于函数
7) #define 表达式可以比函数更强大
8) #define 表达式比函数更容易出错
9) 宏表达式被预处理器处理,编译器不知道宏表达式的存在
10)宏表达式用”实参”完全代替形参,不进行任何运算
11)宏表达式没有任何调用的开销
12)宏表达式中不能出现递归定义
13)宏定义效率高于函数
14)预处理器不会对宏定义进行语法检测
15)宏的使用会带来一定的副作用
¶3、强大的内置宏
编程实验
1 | #include <stdio.h> |
条件编译使用分析
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1
2
3
4
5
6
7
8
9
10
11
#include 的本质是将已经存在的文件内容嵌入到当前文件中
#include 的间接包含同样会产生嵌入文件内容的操作
条件编译可以解决头文件重复包含的编译错误
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif
#if...#else...#endif被预编译处理,而 if...else...语句被编译器处理必然被编译进目标代码
条件编译使我们可以按不同的条件编译不同的代码段,因而可以产生不同的目标代码
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
类似于c语言中的条件语句 if…else…
用于控制是否编译某段代码
1 | #include 的本质是将已经存在的文件内容嵌入到当前文件中 |
实际工作中的条件编译主要用于以下两种情况
不同的产品线共用一份代码
编译产品的调试版和发布版
#error编译分析
用于生成一个编译错误消息
是一种预编译器指示字
用法
1
2
3
4
5
6
7
8
#error message
注:message不需要用引号包围
#error编译指示字用于自定义程序员特有的编译错误消息,类似#warning用于生成编译警告
#error 可用于提示预编译条件是否满足
例子:
#ifndef __cplusplus
#error This file shoud be processed with c++ compiler.
#endif
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
用于生成一个编译错误消息
是一种预编译器指示字
用法
1 | #error message |
- 注:编译过程中的任意错误信息意味着无法生成最终可执行程序。
#line指示字
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1
2
3
#line number filename
filename可以省略
#line的本质是重定义__LINE__和__FILE__
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法
1 | #line number filename |
#pragma指示字
¶1、一般用法:
1
#pragma parameter
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1
2
3
4
5
#ifdef ANDROID20
#pragma message("Complite Android SDK 2.0...")
#endif
注:与#error和#warning不同
#pragma message 不代表程序错误,仅代表一条编译信息
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1
2
3
4
5
6
7
8
#ifndef _FLIE_H_
#define _FLIE_H_
#pragma once
//代码块
#endif
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
未使用 #pragma pack
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 4 8 4 ==> 12
};
//运行结果 sizeof(struct test1) = 12;
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4 ==> 8
};
//运行结果 sizeof(struct test2) = 8;
使用 #pragma pack
#pragma pack(1)
struct test1 // 内存计算
{ //对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 1 1 2
char c2; // 1 3 1
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test1) = 8;
#pragma pack(1)
struct test1 // 内存计算
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 1 2 2
int i; // 1 4 4 ==> 8
};
#pragma pack()
//运行结果 sizeof(struct test2) = 8;
例子:微软面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#pragma pack(8)
struct s1 // 内存计算
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 4 4 4 ==> 8
};
#pragma pack()
#pragma pack(8)
struct s2 // 内存计算
{ //对齐参数 偏移地址 大小
char c; // 1 0 1
struct s1 d; // 4 4 4
double e; // 8 16 8 ==> 24
};
#pragma pack()
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、一般用法:
1 | #pragma parameter |
注:不同的 parameter 参数语法各不相同
¶2、说明
1)用于指示编译器完成一些特定的动作
2)所定义的很多指示字是编译器特有的
3)在不同的编译器间是不可移植的
4)预处理器将忽略他不认识的 #pragma 指令
5)不同的编译器可能以不同的方式解释同一条#pragma指令
¶3、#pragma message(“内容”)
1)message参数在大多数编译器中都有相同的实现
2)message参数在编译时输出编译消息到编译窗口中
3)message用于条件编译中可提示代码的版本信息
例子:
1 | #ifdef ANDROID20 |
¶4、#pragma once 关键字
1)用于保证头文件只被编译一次
2)是与编译器相关的,不一定被支持
3)与#ifdef … #define … #endif的区别
a)效率不如#pragma once
b)支持性比#pragma once好
4)使用时两者结合
1 | #ifndef _FLIE_H_ |
¶5、#pragma pack关键字(用于指定内存的对齐方式)
1)内存对齐
a)不同类型的数据在内存中按照一定的规则排列
b)而不是一定的顺的一个接一个的排列
2)内存对齐的原因
a)CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是 1,2,4,8,16… 字节
b)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
c)某些硬件平台只能从规定的相对地址处读取特定类型数据,否则产生硬件异常
3)struct 占用的内存大小
a)第一个成员起始于0偏移处
b)每个成员按其类型大小和pack参数中较小的一个进行对齐
c)偏移地址必须能够被对齐参数整除
d)结构体成员的大小取其内部长度最大的数据成员作为其大小
e)结构体的总长度必须为所有对齐参数的整数倍
f)编译器在默认情况下按照4字节对齐
例子:
1 | 未使用 #pragma pack |
例子:微软面试题
1 | #pragma pack(8) |
注:gcc编译器暂时不支持 #pragma pack(8) 所以计算结果为20;在不同的编译器可能会有不同的结果
# 运算符
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1
2
#define STRING(X) #X
printf("%s\n",STRING(hello word));
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、含义作用
1)用于在预处理期将宏参数转换为字符串
2)作用是在预处理期完成的,因此只在宏定义中有效
3)编译器不知道#的转换作用
¶2、用法
1 | #define STRING(X) #X |
## 运算符
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1
2
3
#define CONNECT(a,b) a##b
int CONNECT(a,1);
a1 = 2;
¶3、##巧妙使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <stdio.h>
#define STRUCT(type) typedef struct _tag_##type type;\
struct _tag_##type
STRUCT(Student)
{
char* name;
int id;
};
int main()
{
Student s1;
Student s2;
s1.name = "s1";
s1.id = 0;
s2.name = "s2";
s2.id = 1;
printf("s1.name = %s\n", s1.name);
printf("s1.id = %d\n", s1.id);
printf("s2.name = %s\n", s2.name);
printf("s2.id = %d\n", s2.id);
return 0;
}
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、含义作用
1)用于在预处理期粘连两个标识符
2)##的连接作用是在预处理期完成的
3)只在宏定义中有效
4)编译器不知道##的连接作用
¶2、用法
1 | #define CONNECT(a,b) a##b |
¶3、##巧妙使用
1 | #include <stdio.h> |
指针,数组与字符串
¶1、指针的本质分析
¶1) 申明
1
2
int i;
int* p = &i;
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1
2
3
4
5
6
7
const int* p; //p可变, p指向的内容不可变
int const* p; //p可变, p指向的内容不可变
int* const p; //p不可变,p指向的内容可变
const int* const p; //p不可变,p指向的内容不可变
const 在*p之前,p指向的内容不可变
const 在p之前,p不可变
¶2、数组的概念
¶1)声明
1
int a[x];
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1
2
int a[5]= {1,2}; //显式指定
int b[] = {1,2}; //隐式指定
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1
2
3
4
//test.c 文件
int a[] = {1, 2, 3, 4, 5};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//main.c 文件
#include <stdio.h>
int main()
{
extern int* a;
printf("&a = %p\n", &a);
printf("a = %p\n", a);
printf("*a = %d\n", *a);
return 0;
}
gcc环境下编译运行:gcc main.c test.c
运行结果:
&a = 0x804a014
a = 0x1
段错误
b)数组名遇到sizeof表示整个数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main()
{
int a[5] ={1,2,3,4,5};
printf("sizeof(a) = %d\n", sizeof(a)); // 整个数组元素大小 20
return 0;
}
运行结果:
sizeof(a) = 20
¶3、指针的运算
¶1)指针与整数的运算规则为
1
p + n; <——> (unsigned int)p + n*sizeof(*p);
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1
p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1)
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); // 3
printf("%d\n", p0 + p2); // ERROR
printf("%d\n", p0 - p2); // Unknown value
printf("%d\n", p0 - p); // ERROR
printf("%d\n", p0 * p2); // ERROR
printf("%d\n", p0 / p2); // REEOR
return 0;
}
b)指针+数组边界访问数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s); // Key point
char* p = NULL;
printf("pBegin = %p\n", pBegin);
printf("pEnd = %p\n", pEnd);
printf("Size: %d\n", pEnd - pBegin);
for(p=pBegin; p<pEnd; p++)
{
printf("%c", *p);
}
printf("\n");
return 0;
}
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1
a[n] <——> *(a + n) <——> *(n + a) <——> n[a]
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
int main()
{
int a[5] = {0};
int* p = a;
int i = 0;
for(i=0; i<5; i++)
{
p[i] = i + 1;
}
for(i=0; i<5; i++)
{
printf("a[%d] = %d\n", i, *(a + i));
}
printf("\n");
for(i=0; i<5; i++)
{
i[a] = i + 10; // ==> *(i+a) ==> *(a+i) ==> a[i]
}
for(i=0; i<5; i++)
{
printf("p[%d] = %d\n", i, p[i]);
}
return 0;
}
b)指针与数组的混合运算练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1);
int* p2 = (int*)((int)a + 1);
int* p3 = (int*)(a + 1);
printf("%d, %x, %d\n", p1[-1], p2[0], p3[1]);
// p[-1] ==> *( p + (-1) ) ==> *(p-1) ==> a[5] ==> 5
/* 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00 50 00 00 00 小端模式存储数据
==> p2[0] ==> 0x02000000
*/
// p3[1] ==> 3
return 0;
运行结果: 5, 2000000, 3
}
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1
2
3
a+1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*(&a)) ==> (unsigned int)(&a) + sizeof(a)
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1
2
void f(int a[]); <==> void f(int *a);
void f(int a[5]); <==> void f(int *a);
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <stdio.h>
void func1(char a[5])
{
printf("In func1: sizeof(a) = %d\n", sizeof(a)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*a = 'a';
a = NULL;
}
void func2(char b[])
{
printf("In func2: sizeof(b) = %d\n", sizeof(b)); // 数组退化为指针 ==> In func1: sizeof(a) = 4
*b = 'b';
b = NULL;
}
int main()
{
char array[10] = {0};
func1(array);
printf("array[0] = %c\n", array[0]); // array[0] = a
func2(array);
printf("array[0] = %c\n", array[0]); // array[0] = b
return 0;
}
运行结果:
In func1: sizeof(a) = 4
array[0] = a
In func2: sizeof(b) = 4
array[0] = b
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1
typedef type(name)[size];
重定义数组类型:
1
2
typedef int(AINT5)[5];
typedef float(AFLOAT)[10];
数组定义:
1
2
AINT5 iArry;
AFLOAT farry;
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1
int a[]; //a的类型为 int*;
二维数组名同样代表数组元素的地址
1
int m[2][5]; //m的类型为 int(*)[5];
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1
2
void f(int a[5]) <——> void f(int a[]) <——> void f(int *a)
void g(int a[3][3]) <——> void g(int a[][3]) <——> void g(int (*a)[3])
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*)); // ==> P1是一个指针,指向一个函数 ,该函数的类型为 int (int*,int,int (*f)(int*))
int (*p2[5])(int*); // ==> p2是一个数组有5个数组元素,每个数组元素都是函数指针,指向的函数类型为 int(int*)
int (*(*p3)[5])(int*); // ==> p3是一个数组指针,指向的数组有5个元素,每个元素的类型为函数指针,指向的函数类型为 int(int*)
int*(*(*p4)(int*))(int*); // ==> p4是一个函数指针,该函函数的参数为(int*),返回值为一个函数指针指向的函数类型为 int*(int*)
int (*(*p5)(int*))[5]; // ==> p5是一个函数指针,该函数的参数为(int*),函数的返回值为一个数组指针指向的数组类型为int[5]
//将p5用typedef简写
typedef int(ArryType)[5];
typedef ArryType*(FuncType)(int*);
FuncType p5;
return 0;
}
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、指针的本质分析
¶1) 申明
1 | int i; |
p中保存着i的地址
指针是变量保存的是所指向的变量的地址
¶2) *号的意义
a)在指针申明时,*表示所申明的变量为指针
b)在指针使用时,*表示取指针所指向的内存空间的值
c)*类似于一把钥匙,通过这把钥匙可以打开内存,读取内存中的值
¶3)传值调用与传址调用
a)当一个函数体内部需要改变实参的值,则需要使用指针参数
b)函数调用时实参将复制到形参
c)指针适用于复杂数据类型作为参数的函数中
¶4)指针与常量
1 | const int* p; //p可变, p指向的内容不可变 |
¶2、数组的概念
¶1)声明
1 | int a[x]; |
¶2)说明
a)数组是相同类型变量的有序集合
b)a 代表数组第一个元素的起始地址
c)数组包含x个int类型的数据
d)这x*4个字节空间的名字为a
注:a[0],a[1],都是数组中的元素,并非数组元素的名字。数组中的元素没有名字
¶3)数组的大小
a)数组在一片连续内存空间中存储元素
b)数组元素的个数可以显示或隐式指定
1 | int a[5]= {1,2}; //显式指定 |
¶4)数组的本质
a)数组是一段连续的内存空间
b)数组的空间大小为 *sizeof(arry_type)arry_size
c)数组名可以看做指向数组第一个元素的常量指针
d)数组元素的地址和数组元素第一个元素的地址的地址值相同但表示的意义不同
¶5)编程实验
a)验证数组名本质不是常量指针
1 | //test.c 文件 |
1 | //main.c 文件 |
b)数组名遇到sizeof表示整个数组的大小
1 | #include <stdio.h> |
¶3、指针的运算
¶1)指针与整数的运算规则为
1 | p + n; <——> (unsigned int)p + n*sizeof(*p); |
结论:
当指针p指向一个同类型的数组元素时:
p + 1 将指向当前元素的下一个元素
p - 1 将指向当前元素的上一个元素
¶2)指针与指针之间的运算
a)指针之间只支持减法运算
1 | p1 - p2 ; <——> ((unsigned int)p1 - (unsigned int)p2)/sizeof(*p1) |
b)参与减法运算的指针类型必须相同
c)当两个指针指向的元素不在同一个数组中时,结果未定义
d)只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标差
¶3)指针之间的比较运算
a)指针也可以进行比较运算(<, <= ,>, >=)
b)指针关系运算的前提是同时指向同一个数组中的元素
c)任意两个指针之间的比较运算( ==, != )无限制
d)参与运算的两个指针类型必须相同
¶4)编程实验
a)指针运算
1 | #include <stdio.h> |
b)指针+数组边界访问数组
1 | #include <stdio.h> |
¶4、数组的访问方式
¶1)访问方式
下标的形式访问数组 a[1];
*指针的形式访问数组 (a+1);
¶2)下标形式与指针形式的转换
1 | a[n] <——> *(a + n) <——> *(n + a) <——> n[a] |
¶3)两者的优缺点
a)指针以固定增量在数组中移动时,效率高于下标形式。
b)指针增量为 1 且硬件具有硬件增量模型时,效率更高
注意:现代编译器的生成代码优化率已经大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护的角度看,下标形式更优。
¶4)编程实验
a)指针与数组的访问
1 | #include <stdio.h> |
b)指针与数组的混合运算练习
1 | #include <stdio.h> |
¶5、a和&a的区别
a 为数组首元素的地址
&a 为整个数组的地址
a 和 &a 的区别在于指针运算
1 | a+1 ==> (unsigned int)a + sizeof(*a) |
¶6、数组参数
¶a)数组作为参数时,编译器将其编译成对应的指针
1 | void f(int a[]); <==> void f(int *a); |
结论:一般情况下,当定义的函数中数组参数时,需要定义另一个参数来表示数组大小。
¶b)编程实验
1 | #include <stdio.h> |
¶7、数组类型
¶1)c语言中的数组有自己特定的类型
数组的类型由元素类型和数组大小共同决定
例: int arry[5] 的类型为 int[5]
¶2)定义数组类型
c语言通过 typedef 为数组类型重命名
1 | typedef type(name)[size]; |
重定义数组类型:
1 | typedef int(AINT5)[5]; |
数组定义:
1 | AINT5 iArry; |
¶8、数组指针
¶1)声明
可以通过数组类型定义数组指针:ArryType pointer;*
也可以直接定义: *type(pointer)[n];
pointer 为数组指针变量名
type 为指向的数组的类型
n 为指向的数组的大小
¶2)作用
a)数组指针用于指向一个数组
b)数组名是数组首元素的起始地址,但并不是数组的起始地址
c)通过将取地址符&作用于数组名可以得到数组的起始地址
¶9、指针数组
指针数组是一个普通的数组
指针数组中的每一个元素为指针
指针数组的定义:type pArry[n];*
type 为数组中每个元素的类型*
PArry 为数组名
n 为数组大小
¶10、二维指针
指向指针的指针
指针会占用一定的内存空间
可以定义指针的指针来保存指针的地址
¶1)二维数组与二级指针
二维数组在数内存中以一维的方式排布
二维数组中的第一维是一维数组
二维维数组中的第二维才是具体的值
二维数组的数组名可以看做常量指针
¶2)数组名
一维数组名代表数组首元素的地址
1 | int a[]; //a的类型为 int*; |
二维数组名同样代表数组元素的地址
1 | int m[2][5]; //m的类型为 int(*)[5]; |
结论:1. 二维数组名可以看做是指向一维数组的常量数组指针; 2. 二维数组可以看做是一维数组; 3. 二维数组中的每个元素都是同类型的一维数组; 4. c语言中的数组在函数参数中会退化成指针
¶3)二维数组参数
二维数组参数同样存在退化的问题
二维数组可以看做是一维数组
二维数组中的每个元素是一维数组
二维数组的第一个参数可以省略
1 | void f(int a[5]) <——> void f(int a[]) <——> void f(int *a) |
¶11、指针阅读技巧解析
¶1)基本规则
- 从最里层的圆括号中未定义的标识符看起
- 首先往右看,再往左看
- 遇到圆括号或方括号时可以确定部分类型,并调整方向
- 重复2,3步骤,直到阅读结束
¶2)实例分析
1 | #include <stdio.h> |
野指针
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、含义
指针变量中的值是非法的内存地址,进而形成野指针
野指针不是 NULL 指针,是指向不可用内存地址的指针
NULL 指针并无危害,很好判断也很好调试
c语言无法判断一个指针保存的地址是否合法
¶2、野指针的由来
1)局部指针变量没有初始化,保存随机值
2)指针所指变量在指针之前被销毁
3)使用已经释放过得指针
4)进行了错误的指针运算,内存越界
5)进行了错误的强制类型转换
¶3、怎么避免野指针
1)绝不返回局部变量和局部数组地址
2)任何变量在定义后必须0初始化
3)字符数组必须确认 0 结束符后才能成为字符串
常见内存错误
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、常见内存错误
1)结构体成员指针未初始化
2)结构体指针未分配足够的内存
3)内存分配成功但为初始化
4)内存操作越界
¶2、怎么避免内存操作错误
1)动态内存申请后,应立即检查指针,值是否为NULL
2)free 指针过后必须立即赋值为NULL
3)任何与内存操作相关的函数都必须带长度信息
5)malloc 操作和 free 操作必须匹配,防止内存泄漏和多次释放
6)在哪个函数中malloc就要在哪个函数中free
C语言中的字符串
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
int main()
{
char ca[] = {'H', 'e', 'l', 'l', 'o'};
char sa[] = {'W', 'o', 'r', 'l', 'd', '\0'};
char ss[] = "Hello world!";
char* str = "Hello world!";
printf("%s\n", ca); // Unknown result
printf("%s\n", sa); // world
printf("%s\n", ss); // hello world!
printf("%s\n\n", str);// hello world!
printf("ca = %p\n", ca); // Unknown result
printf("sa = %p\n", sa); // world
printf("ss = %p\n", ss); // hello world!
printf("str = %p\n", str);// hello world!
return 0;
}
运行结果:
Hello ����Hello world!
World
Hello world!
Hello world!
ca = 0xbfa1e5d3
sa = 0xbfa1e5cd
ss = 0xbfa1e5df
str = 0x8048620
结果分析:str地址明显区别于ca sa ss,因为字符串字面量为常量,而ca sa ss为栈上零时分配空间的字符数组
a)字符串编程练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
int main()
{
char b = "abc"[0]; // b = 'a'
char c = *("123" + 1); // c = '2'
char t = *""; // t = '\0'
printf("%c\n", b);
printf("%c\n", c);
printf("%d\n", t);
printf("%s\n", "Hello");
printf("%p\n", "World");
return 0;
}
运行结果:
a
2
0
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1
2
char *s = "hello";
printf("%s\n",strlen(s));
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1
int snprintf(char* buffer, int buff_size ,const char* fomart,...);
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、字符串的概念
¶1)字符串是程序中的基本元素之一
字符串是有序字符的集合
c语言中没有字符串的概念,c语言通过特殊的字符数组模拟字符串
c语言中的字符串是以 ‘\0’ 结尾的字符数组
¶2)字符数组与字符串
在c语言中,双引号引用的单个或者多个字符是一种特殊的字面量
储存于程序的全局只读存储区
本质为字符数组,编译器自动在结尾加上’\0’字符
字符串字面量可以看做一个常量指针
字符串字面量中的字符不可改变
字符串字面量至少包含一个字符
字符串相关函数均以第一个出现的’\0’作为结束符
编译器总是会在字符串字面量的末尾添加’\0’
¶3)编程实验
a)验证字符串的本质
1 | #include <stdio.h> |
a)字符串编程练习
1 | #include <stdio.h> |
¶2、符串的长度
字符串的长度就是字符串所包含的字符的个数
字符串长度指的是第一个’\0’前出现的字符个数
通过’\0’结束符来确定字符串的长度
函数 strlen 用于返回字符串的长度
1 | char *s = "hello"; |
字符串之间的相等比较需要用 strcmp 完成
不可直接用 == 进行字符串直接的比较
完全相同的字符串字面量 == 比较结果为false
注意:一些现代编译器能够将相同的字符串字面量映射到同一个无名数组,因此 == 比较结果为true
编程时:不编写依赖特殊编译器的代码
¶3、snprintf函数
snprintf函数本身是可变参数函数,原形如下
1 | int snprintf(char* buffer, int buff_size ,const char* fomart,...); |
注意: 当函数只有3个参数时,如果第三个参数没有包含格式化信息,函数调用没有问题;相反,如果第三个参数包含了格式化信息(%d, %s , %p ,…),但缺少后续对应参数,则程序为不确定
动态内存分配
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1
2
void* malloc(size_t size);
void free(void* pointer);
3)使用
1
type* p = (type*)malloc(sizoef(type)*size);
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1
void* calloc(size_t num ,size_t size);
使用
1
type* p = (type*)calloc(num,sizeof(type))
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1
void* realloc(void* pointer,size_t new_size);
使用
1
2
type* p1 = (type*)malloc(sizoef(type)*size);
type* p2 = (type*)realloc(p1,new_size);
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、动态内存分配的意义
c语言的一切操作都是基于内存的
变量和数组都是内存的别名
内存分配由编译器在编译期间决定
定义数组的时候必须指定数组的长度
数组长度是在编译期就必须确定的
需求:
程序运行过程中,可能你需要使用一些额外的内存空间
¶2、malloc 和 free
1)malloc 和 free 用于执行动态内存的分配和释放
a)malloc 分配的是一块连续的内存
b)malloc 以字节为单位,并且不带任何类型的信息
c)free 用于将动态内存归还系统
2)函数原型
1 | void* malloc(size_t size); |
3)使用
1 | type* p = (type*)malloc(sizoef(type)*size); |
注意:
malloc 和 free 是库函数,不是系统调用
malloc 实际分配的内存可能比请求的多
不能依赖不同平台下的 malloc 行为
当请求的动态内存无法满足时,malloc 返回NULL
当 free 的参数为 NULL 时,函数直接返回
¶3、calloc 和 realloc
¶1)calloc
calloc 在内存中动态地址分配num个长度为size的连续空间,并且将每一个字节都初始化为0
calloc 函数原型
1 | void* calloc(size_t num ,size_t size); |
使用
1 | type* p = (type*)calloc(num,sizeof(type)) |
¶2)realloc
a)realloc 用于修改一个原先已经分配的内存块大小
b)在使用realloc之后应该使用其返回值
c)当pointer的第一参数为NULL时,等价于malloc
函数原型
1 | void* realloc(void* pointer,size_t new_size); |
使用
1 | type* p1 = (type*)malloc(sizoef(type)*size); |
小知识:内存包含两个信息地址,长度
程序中栈
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、说明
栈是现代计算机程序里最为重要的概念之一
栈在程序中用于维护函数调用上下文
函数中的参数和局部变量储存在栈上
栈保存了一个函数调用所需的维护信息
参数
返回值
局部变量
调用上下文
…
¶2、函数调用的过程使用栈
调用函数的活动记录位于栈的中部
被调用的函数活动记录位于栈的顶部
¶3、函数调用栈上的数据
函数调用时,对应的栈空间在函数返回前是专用的
函数调用结束后,栈空间将被释放,数据不再有效,无法传递到函数外部
程序中栈程序中的堆
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
堆是程序中一块预留的内存空间,可由程序自由使用
堆中被程序申请使用的内存在被主动释放前一直有效
c语言程序中通过函数的调用获得堆空间
头文件: malloc.h
free:将堆空间返还给系统
系统对堆空间的管理方式: 空间链表法,位图法,对象池法等等。
程序与进程
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
程序和进程不同
程序是静态概念,变现形式为一个可执行文件
进程是动态概念,程序由操作系统加载运行后得到进程
每个程序可以对应多个进程
每个进程只能对应一个程序
程序中的静态存储器
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
静态储存区随着程序的运行而分配空间
静态存储区的生命周期直到程序运行结束
在程序的编译期静态存储区的大小就已经确定
静态存储区主要用于保存全局变量和静态局部变量
静态存储区的信息最终会保存到可执行程序中去
程序的内存布局
堆栈段在程序运行后在正式存在,是程序运行的基础
1
2
3
4
5
.text段 存放的是程序中的可执行代码
.rodata段 存放着程序中的常量值,如:字符串常量
.data段 存放的是已经初始化的全局变量和静态变量
.bss段 存放的是未初始化或初始化为0的全局变量和静态变量
.comment段 存放注释,不被烧写进程序
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
堆栈段在程序运行后在正式存在,是程序运行的基础
1 | .text段 存放的是程序中的可执行代码 |
程序术语对的对应关系
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
静态存储区通常指程序中的 .bss 和 .data 段
只读存储区通常指程序中的 .rodata 段
局部变量所占的空间为栈上的空间
动态空间为堆的空间
程序可执行代码存放与 .text 段
c语言中的函数
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、函数的由来
程序 = 数据 + 算法
c程序 = 数据 + 函数
¶2、面向过程的程序化设计
1)面向过程是一种以过程为中心的编程思想
2)首先将复杂的问题分解为一个个容易解决的问题
3)分解过后的问题可以按照步骤一步步完成
4)函数面向过程在c语言中体现
5)解决问题的每一个步骤可以用函数来实现
¶3、声明和定义
1)声明的意义在于告诉编译器程序单元的存在
2)定义则明确与指示程序单元的意义
3)c语言中通过 extern 进行程序单元的声明
4)一些程序单元在申明是可以省略 extern
5)严格意义上的声明和定义并不相同
¶4、函数参数
函数参数在本质上与局部变量相同在栈上分配空间
函数参数的初始值是函数调用时的实参值
函数参数求值顺序依赖于编译器的实现
¶5、程序中的顺序点
1)程序中存在一定的顺序点
a)顺序点指的是程序执行过程中修改变量值的最晚时刻
b)在程序达到顺序点的时候,之前所做的一切操作必须完场
2)c语言中的顺序点
a)每个完整表达式结束时,即分号处
b)&& 、|| 、?: 、 以及逗号表达式的每个参数计算后
c)函数调用时所有实参求值完成后(进入函数体前)
¶6、参数入栈顺序
1)调用约定
a)当函数调用发生时
参数会传递给被调用的函数
而返回值会被返回给函数调用者
b)调用约定描述参数如何传递到栈中以及栈的维护方式
参数传递顺序
调用栈清理
c)调用约定是预定义的可以理解为调用协议
d)调用约定通常用于库调用和库开发的时候
从右到左依次入栈: _stdcall , _cdecl , thiscall
从左到右依次入栈: _pascal , _fastcall
A编译器 ==> 主程序 ==> 库文件 <== B编译器
c语言中的函数进阶
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1
2
3
4
5
6
7
int main();
int main(int argc);
int main(int argc, char* argv[]);
int main(int argc, char* argv[],char* env[]);
argc ——命令行参数个数
argv ——命令行参数数组
env ——环境变量数组
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1
int add(int i, int j) 的类型为 int(int ,int)
c语言通过 typedef 为函数类型重命名
1
typedef type name(parameter list)
例子:
1
2
typedef int f(int ,int);
typedef void p(int);
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、main函数的概念
¶1)说明
c语言中main函数称为主函数
一个c程序是从main函数开始执行的
¶2)mian函数的本质
main函数是操作系统调用的函数
操作系统总是将main函数作为应用程序的开始
操作系统将main函数的返回值作为程序退出状态
¶3)main函数的参数
程序执行时可以向main函数传递参数
1 | int main(); |
¶4)函数参数传递
c语言中只会以值拷贝的方式传递参数
当函数传递数组时:
将怎个数组拷贝一份传入数组(错误)
将数组名看做常量指针传数组首元素的地址
c语言以高效作为最初的设计目标
a)参数传递的时候如果拷贝整个数组执行效率将大大下降
b)参数位于栈上,太大的数组拷贝将导致栈的溢出
现代编译器支持在main函数函数之前调用其他函数
¶2、函数类型
c语言中的函数有自己特定的类型
函数的类型由返回值,参数类型和参数个数共同决定
1 | int add(int i, int j) 的类型为 int(int ,int) |
c语言通过 typedef 为函数类型重命名
1 | typedef type name(parameter list) |
例子:
1 | typedef int f(int ,int); |
¶3、函数指针
函数指针用于指向一个函数
函数名是执行函数体的入口地址
可以通过类型定义函数指针: FuncType pointer;*
也可以直接定义: *type (pointer)(parameter list);
pointer为函数指针变量名
type 为所指函数的返回值类型
parameter list 为所指函数的参数类型列表
¶4、回调函数
回调函数是利用函数指针实现的一种调用机制
回调机制的原理
调用者不知道具体时间发生时需要调用的具体函数
被调用函数不知道何时被调用,只知道需要完成的任务
当具体事件发生时,调用者通过函数指针调用具体函数
回调机制中的调用者和被调函数互不依赖
函数可变参数
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
¶1、c语言中可以定义参数可变的函数
参数可变函数的实现依赖于 stdarg.h 头文件
va_list 参数集合
va_start表示参数访问的开始
va_arg取具体参数值
va_end标识参数访问结束
¶2、可变参数的限制
1)可变参数必须从头到尾按照顺序逐个访问
2)参数列表中至少要存在一个确定的命名参数
3)可变参数函数无法确定实际存在的参数的数量
4)可变参数函数无法确定参数的实际类型
注意: va_arg 中如果指定了错误的类型,那么结果是不可预测的; 可变参数必须顺序访问,无法直接访问中间的参数值
函数与宏分析
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
0%
宏是由预处理器直接替换展开的,编译器不知道宏的存在
函数是由编译器直接编译的实体,调用行为由编译器决定
多次使用宏会导致最终的可执行程序的体积增大
函数是跳转执行,内存中只有一份函数体存在
宏的效率比函数要高,因为是直接展开,无调用开销
函数调用会创建活动记录,效率不如宏
可以用函数完成的绝对不用宏
宏的定义中不能出现递归定义
递归函数
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1
2
3
4
5
6
7
8
9
int fac(int n)
{
if(1==n)
return 1;
else if(2==n)
return 1;
else if(2<n)
return fac(n-1) + fac(n-2);
}
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1
2
3
4
5
6
7
8
9
10
11
12
13
void han_move(int n,char a, char b, char c)
{
if(n == 1)
{
printf("%c-->%c\n",a,c);
}
else
{
han_move(n-1,a,c,b);
han_move(1,a,b,c);
han_move(n-1,b,a,c);
}
}
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
¶1、递归的数学思想
1)递归是一种数学上分而自治的思想
2)递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
3)递归需要有边界条件
a)当边界条件不满足时,递归继续进行
b)当边界条件满足时,递归停止
¶2、递归函数
1)函数体中存在自我调用的函数
2)递归函数是递归的数学思想在程序设计中的应用
a)递归函数必须有递归出口
b)函数的无限递归将导致程序栈溢出而崩溃
¶3、递归函数设计技巧
¶4、斐波拉契数列递归解法
1,1,2,3,5,8,13,21,…
1 | int fac(int n) |
¶5、汉诺塔问题
1)将木块借助 B由A柱移动到c柱
2)每次只能移动一个木块
3)只能出现小木块在大木块之上
问题分解
将n-1个木块借助C柱移动到B柱
将最底层的唯一木块直接移动到C柱
将n-1个木块借助A柱由B柱移动到C柱
1 | void han_move(int n,char a, char b, char c) |
函数设计原则
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1
2
char s[64];
int len = strlen(strcpy(,"android"));
函数名与返回值类型在语意上不可冲突
1
2
3
4
5
char c = getchar(); //getchar 返回值为 int
if(EOR == c)
{
}
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习
优秀的代码具有自注性,直接可以读出函数的功能
函数从意义上应该是一个独立的功能模块
函数名要在一定程度上反映函数功能
函数参数名要能体现参数的意义
尽量避免在函数中使用全局变量
当函数参数不应该在函数内部被修改时,应该加上 const 申明修饰
如果参数是指针,且仅作为输入参数,则应该加上 const 申明
不能省略返回值的类型
如果函数没有返回值,那么应该声明为 void 类型
对函数参数检查有效性
对于指针参数的检查尤为重要
不要返回指向"栈内存"的指针
栈内存在函数结束时会被自动释放
函数体的规模要小,尽量控制在"80"行代码之内
相同的输入对应相同的输出,避免函数带有"记忆"功能
避免函数有过多的参数,参数尽量控制在"4"个以内
有时候函数不需要返回值,但为了支持灵活性,如支持链式表达,可以附加返回值
1 | char s[64]; |
函数名与返回值类型在语意上不可冲突
1 | char c = getchar(); //getchar 返回值为 int |
本文来自狄泰软件视频自学记录,有兴趣学习可以淘宝搜索“狄泰软件学院”购买视频学习